API管理平台卡死报错504
0、问题背景
最近,umeapi 经常出现无法访问的情况,页面长时间加载后报错 504(网关超时),这种情况已经发生了两次以上。每次都需要重启才能恢复。为了避免类似问题的再次发生,必须进行排查并找出根本原因。
1、问题排查
1、确认服务状态:
首先,我们检查了 umeapi 进程,确保其正常运行,服务未崩溃。
2、查看日志: 通过分析日志,发现能够获取到访问的用户名,但其他服务请求没有收到响应。这表明问题不在前端,而是后端接口或数据库出现了卡顿或异常。
可能的原因
1、代理地址超时: 排查了运维代理地址,未发现超时问题。
2、定时任务问题: 检查了所有的定时任务,怀疑定时任务在操作更新 Redis 时可能导致了卡死。
3、数据库优化: 为了解决数据库压力,我们执行了大表优化,清除了一些无用的接口历史记录,将 11g 的响应表缩小至 1g 以下。
2、解决办法
对于可能出现的问题,暂时应对办法如下:
1、排查后确认问题不在运维代理上。
2、优化了定时任务代码,增加了异常处理和错误日志记录。未来将逐步按日志规范整理所有接口。
3、与数据库团队沟通,怀疑大表的历史记录影响了性能。已编写并测试了删除历史数据的脚本,将其应用到生产环境。该脚本会自动删除 ume_action、ume_action_and_parameter、ume_request 和 ume_response 四个表中的历史记录,从而减轻数据库压力。
OK,那现在只能从数据库下手了。那么?
恰好早上db同学发来飞书。
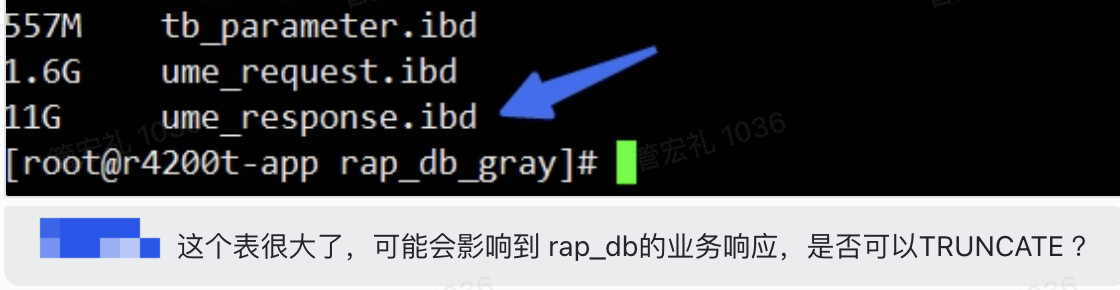
好家伙竟然11g了。
DB 同事给出的解决方案如下:
- 方案 1: 使用
TRUNCATE清空表。 - 方案 2: 分表处理。
然而,对于我们来说,直接 TRUNCATE 表是不现实的,因为这样会导致系统无法运行。分表虽然可行,但实现起来较为麻烦。因此,我开始考虑是否可以从业务侧进行优化来解决这个问题。
2.1、问题分析
2.1.1、业务流程梳理
我们系统的业务逻辑是先获取一个大 JSON 数据对象,分为 module、page、action 和 parameter 四层。在这其中,我们主要关注的是 action 和 parameter。
主要处理两种逻辑:
- 新增: 将接口的基本信息存入
ume_action,请求信息存入ume_request,响应信息存入ume_response。 - 更新: 类似新增操作,但将旧记录的状态置为 0,然后插入新记录(原本是为了保留历史记录,因此没有直接修改旧记录,而是插入新记录)。
2.1.2、数据库表分析
涉及到的四个主要表:
ume_action— 存储接口信息,记录接口的使用状态。ume_action_and_parameter— 存储接口与请求响应参数的关联。ume_request— 存储请求信息。ume_response— 存储响应信息。
其中,ume_response 存储了接口的返回值,因为返回值的 JSON 数据量大,所以这个表也变得非常庞大。
2.1.3、数据表总结
当前,历史记录量达到了 270,369 条,而活跃数据仅为 9,000 条,差距较大。实际上,很多历史记录都不再有用,可以通过定时任务清除不再使用的数据。
2.2、解决方案
- 统计活跃接口与历史接口:
通过
ume_action的status字段统计出正在使用的接口和历史接口。 - 遍历并删除历史数据:
遍历
status为 0 的接口,查找对应的action_and_parameter记录,并根据关联关系删除request、response和action_and_parameter表中的数据。
代码实现流程
- 定时任务:
使用
@Scheduled注解,设置每晚 10:30 执行清理任务。 - 执行定时任务方法:
timedDeletionUselessInterfaces方法将从数据库中获取status为 0 的接口列表,批量处理并删除相关记录。 - 批量处理:
每次批量处理 1000 条记录,调用
processActionList方法处理当前批次。 - 删除记录:
通过
actionService和parameterNewService执行批量删除操作。 - 日志记录:
在每个重要步骤都使用
logger记录关键信息,例如删除的记录数等。 - 继续处理或结束: 如果当前批次未处理完,继续下一轮;否则,结束任务。
3、总结
通过对 umeapi 系统卡死问题的排查和处理,我们识别出数据库表过大的问题,并通过定时任务清理历史记录有效减轻了数据库的负担。虽然这只是一个临时解决方案,但它为系统稳定性提供了保障。在未来,我们还将进一步优化数据库和代码,以避免类似问题的再次发生。