校招之八股文
2022校招落幕,这是在此期间整理的笔试面试的基础知识。
HR面(国企面)
hr面试,顾名思义,就是hr来面试。
一般会从性格特点,未来规划,聊聊过去几个方面来问。
技巧:
输出观点,会讲故事。(奇葩说那些人为啥可以逼逼叨你还觉得有道理?很大程度是因为他们擅长讲故事)
善于引导,掌控节奏。(不能只听他问,引导到自己擅长的一些问题上来。)
自我介绍3min(500字左右)
针对自己的岗位准备自我介绍。
校园经历-实习经历-岗位理解。
网络安全
我认为网络安全是非常重要的,在滴滴实习的时候也深有体会,无论是做出行安全还是数据信息安全都让我感触颇深,习总书记也说,没有网络安全就没有国家安全。因此我认为这是一份非常有意义的工作。先哲功已就,我辈当争先。倘若通过我所做的工作,能够为国家的网络安全做一些事情,那一定是我莫大荣幸。
数据分析
随着大数据时代的到来,数据的价值显得越来越重要,良好的收集、管理、分析和使用势必会对植物所乃至国家提供科学的决策依据,赋能和反哺给我们的科学研究,但现阶段无论是互联网公司还是企事业单位,其实对于数据的挖掘和利用还远远不够,因此我很荣幸能够在这其中,利用自己的专业知识和个人的兴趣,通过技术管理手段,挖掘数据中的价值,助力我们的科学研究,我认为这是一件非常有意义的事情。
如何看待科研院所?
大浪淘沙,阅尽千帆过后,最后的剩下了才是自己的初心,也是坚定不移的选择。
我想说的是选择研究所不是怦然心动后的一腔热血,而是我深思熟虑后坚定不移的选择。
为什么要选择给我SP?
1.对所负责的工作可以很好的完成,对及时性和准确性负责。
- 对导流场景的case的优先级进行梳理,对上下游接口,服务的调用进行梳理。制定完备的测试计划,开发阶段-准入-模块测试-准出阶段-联调-预发-上线。
- 对手头的项目和工作进行分级,重要且紧急。很好的负责了今年以来的几个重大项目。
2.对所做的工作,有自己的思考和探索。(提效)
- 将模块级自动化介入oe流水线系统,建立准入准出的机制。(提升了测试效率)
- 对dcm框架进行了服务的接入和testenv的改造。(提升了效率和稳定性)
- 书写一些列新手教程和文档,对后来人有所帮助。
给一个录取你的理由?
因为我有足够的积累,并且一直在路上,所以我有无限的可能。
你有什么缺点?
1.我的缺点是很容易受身边的人影响。比如我本科的时候室友都比较贪玩,整天跟着他们打游戏啥的,学习成绩就不太好,还好最后快毕业的时候幡然醒悟,努力学习考上了研究生,也正是有了这段经历,让我深刻的体会到了环境对人的影响。因此无论是工作和学习我都希望能在一个好的团队氛围中。
2.我的缺点就是不知道如何去拒绝别人。同事要我帮忙我会很快答应,尽管自己手头上也有很多需要完成的工作。我会慢慢地学会说“不”,在自己忙的时候尽量告诉同事自己也有很多事情要做,帮不了他们的忙。因为一味地帮助别人是对自己的不负责任另外对同事也不好。
你有什么优点?
1.我的优点就是比较细心和认真吧,面对重复性的枯燥工作能够不慌不忙的做完,比如之前有帮研招办的老师干活,将几千份报名表和学号对应找出来,还要排好顺序,当时我们几个同学做了正正一天,有几个同学到后来都已经抓狂坐不住了,而我还可以平静的把工作完成。
2.我的性格比较开朗,交流能力比较强,平时也喜欢交朋友,喜欢和同学或者同事交流,与大家都可以相处的很好,通过交流经常能发现很多学习和工作上的不足,这也给了我提升和完善自己的机会。
平时通过什么方式来学习知识技术?
平时我会通过看书,b站,github,csdn等技术网站来学习感兴趣的知识。不过在学习期间我也发现一个问题,那就是这种为了学习而学习往往效率都很低,比如几百页的书看了几页就不看了,几百小时的教程看了几个小时就搁置了。像刚来滴滴实习的时候对go语言和一些自己开发测试框架都很陌生,看教程自学了几天还是云里雾里,直到自己亲自参与了项目,才渐渐的对整体的流程有了一定的了解。所以我觉得以任务为驱动的学习方式才是更高效的,纸上谈兵永远不如亲自实践。况且通过学习能解决实际工作中的问题,也会让我特别有成就感。
有经历过人生的至暗时刻,或情感波动?
我印象比较深的是刚来北京读研的一段时间,我觉得是我比较down的时刻,也是我成长比较关键的一个节点。
背景:因为本科的时候比较贪玩,也没有一个明确的人生规划,所以就孤注一掷的考研了,妄想通过考验就可以咸鱼翻身。
实际上等真的考上了之后呢,咸鱼翻身还是咸鱼!在考研的时候可以把所有的问题掩盖住,但等考上了之后,所有的问题又暴露了出来,我还是曾经那个少年,除了学历没有一丝改变。那段时间我特别焦虑,不知道考研的意义是什么,不知道以后要做什么,于是开始焦虑,陷入了自我怀疑和自我打气相交替了一个阶段,最后花了一段时间终于考虑了清楚,明确了自己的未来的发展之后,一切都守得云开见月明了。
所以考研对我来说最大的价值,其实并不是提升了学历或者学习到了多少知识,最后重要的是帮我暴露出之前存在的问题,让我找到了未来前进的方向,这对我的人生来说才是最有意义的。
对于未来的职业人生规划?
在最后一年的读书生活,也就是研三这一年,赶紧把毕业论文写完,然后进行入职前的实习,提前熟悉公司的业务。
正式工作的第一年,成为一名合格的工程师,在必要的辅导或标准流程支持下,能独立负责一个子模块或项目的具体任务,对及时性和准确性负责。
正式工作的第二年,成为独当一面的工程师,独立承担某一模块/专业领域的职责,能够高质量完成工作,能把握一个系统团队的整体实现,在推行过程中能提炼新的方法或方案,或对现有方案提出改进建议。
正式工作的第三年,有一定架构能力的工程师,对于一个较为复杂,涉及多个功能点的业务系统,或者技术难度较高的底层系统,能做良好的架构拆解并实现- 对相关的多个业务系统的交互有了解- 可以胜任子系统级别的测试方案、自动化方案的设计,担任项目负责人,承担评估技术难度与风险、分解目标,推动实施等职责。
正式工作的第五年,成为子系统负责人,能把握一个子系统的技术深度,给出技术决策和长期规划,能了解系统内多个业务子系统的情况,并有自己的思考- 认同为部门级相关领域专家(如性能、自动化、安全测试等);能够代表部门技术水平,解决此领域复杂技术问题。
不能好高骛远,暂时先做个五年规划,朝着每个阶段的目标去努力。
在工作中遇到困难或难以解决怎么办?
80%先对问题主动思考,带着问题去百度谷歌寻求解决办法,避免请教他人百度就可以解决的肤浅问题。
15%主动尝试,只有在自己主动尝试了不同的问题解法后,“见缝插针” 与 “统一记录”,带着这些尝试后的结果再去请教,别人也会更愿意提供帮助。
5%找同事或老板请教,大家一起探讨。
在实习中学到了什么?
1.保持终身学习的热情和能力。
2.分清楚事情的轻重缓急,这样才能更游刃有余的在不同工作内容之间进行切换。
3.人际交往非常重要,即使是技术开发岗,其实工作中绝大部分时间都是在和人沟通和协作。
在实习工作中遇到印象最深的事故是什么?如何解决的。
star法则,事前,事中,事后。
线上打印两次public日志
Situation问题背景
新增了愿等红包区间随机生成的功能后,上线后策略同学在A/B实验时发现,实验组90%以上的订单会多打印一次public日志,两个日志时间基本一致。但调用的随机红包区间不同,也就意味着是执行了两次不同的函数。
Task任务目标
排查线上问题,找到重复打印日志的原因。
Action行动
从业务api层开始排查,一直到athena-api到athena-predict业务层逐级定位,追踪,排查,测试。找api的同学帮忙查看api的调用,发现业务api调用athena-api接口调用了一次,而athena-api调用athena-predict了两次。所以可以定位是athena-predict的问题。最终找到是由于实验组新增加了愿等红包的随机函数,大概率是apollo_setting_v3.go文件中func GenIntervalSequence()函数中这句随机种子代码导致了实验组耗时增加到100+ms。
1
rand.Seed(time.Now().UnixNano())
又由于athena-predict的超时时间是100ms,进而导致轮询接口请求超时,因此在线上出现predict接口请求两次的现象。
问题难点
- 由于超时时间较短(毫秒单位),线上日志看起来是同一时间打印的(秒为单位),没有明显的先后顺序,因此造成了视觉障碍,影响了定位判断。
- 通过模拟线上的环境和构造模拟真实的数据,来排除验证非代码逻辑问题,耗费了时间。
Result结果
解决办法
- 目前解决办法:增加api调用的超时时间配置。(治标)
- 期待解决办法:可以优化随机函数,减少程序耗时(治本)
思考与改进
- 业务新增加带循环的函数,需要进行接口压测,记录qps耗时等业务指标,qa同学要做到心中有数,梳理可能出现的问题。给rd和策略同学予以提醒。(ps:虽然这次也做了压测,但是没有形成有质量的压测结论和问题预期,给rd测完后没有继续跟踪压测结论)
- 以后再出现这类无明显的代码逻辑问题,可以从性能角度进行分析,减少通过证明代码逻辑没问题所做的无用功。(依赖经验)
轮训接口和手动追加不同
你是怎么定位线上问题的?
1、如果线上出现了问题,我们更多的是希望由监控告警发现我们出了线上问题,而不是等到业务侧反馈。所以,我们需要对核心接口做好监控告警的功能。
2、如果是业务代码层面的监控报警,那我们应该是可以很快地定位出是哪儿的问题,毕竟告警逻辑都是我们写的嘛。如果是服务器资源/所依赖的中间件告警,那我们可能就要花点时间去排查啦。
3、不管怎么样,无论是系统告警还是是业务侧反馈系统或者接口出了问题。我们要想想在近期有没有发布过系统,如果近期发布过系统,判断能不能立马回滚到上一个版本,恢复系统平稳正常运行(在线上环境下,可用性是相当重要的)。回滚的时候要考虑接口有无依赖性,是否需要跟业务侧同步此次的回滚以及做相关的配合。
4、因为线上大多数的问题都来源于系统的变更,可能我们只是变更了很少的代码,但只要有一丝的逻辑没留意到,就真的很可能会导致出现问题,回滚很可能是最快能恢复线上正常运行的办法。
5、如果近期都没发布过系统,是系统告的警,那追踪下告警和报错日志,应该是可以很快地就能定位出问题。
6、如果不是系统告的警,是业务侧反馈出了问题,那这时候需要业务侧明确是哪个具体的功能/接口出了问题,有没有保留请求入参,有没有返回错误的信息,有何现象
7、知道了问题的现象之后,就需要根据经验排查可能是哪块出了问题了。我的经验一般是:先查存储侧有没有瓶颈(MySQL 的CPU有没有飙高,主从同步延迟是否很大,有没有慢SQL。Redis是不是内存满了,走了淘汰策略。搜索引擎有没有慢Query),把该服务所依赖的中间件的指标看一遍,这个过程中也要去看看服务接口的QPS/RT相关的监控。如果有某项指标不对劲,那顺着写入逻辑也应该很快能看出来
8、一般到这里,大多数的问题都能查出来。可能是逻辑本身的问题,可能是请求入参导致慢查询,可能是中间件的网络抖动,可能是突发或者异常请求的问题。
9、如果都不是,回归到应用和机器本身的监控:应用GC的表现、机器本身的网络/磁盘/内存/CPU 各种的指标有没有发现异常的情况。这里可能是需要运维侧一起配合看看有没有做过改动。
10、要是还定位不出来,看能不能复现,能复现都好说,肯定是能解决的。
11、要是不能复现,只能在怀疑的地方打上详细的日志再好好观察(问题定位不出来,很多时候就是日志不够详细,而日志在正常情况下也不应该打太多)
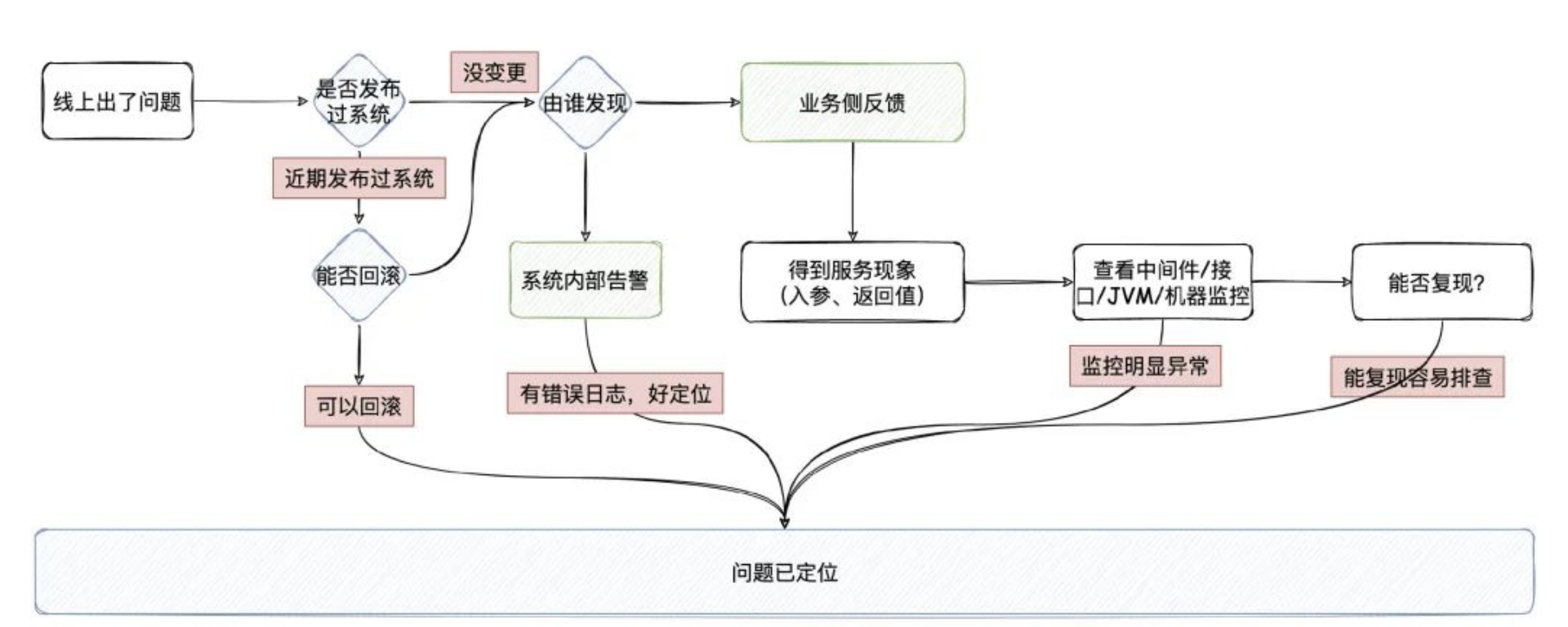
综合上面几点联合考虑,然后视产品发布日期来决定,如果产品发布日期临近,修改一些不太严重、出现不太频繁的bug反而可能得不偿失,带来其他的风险,因此此时仅仅将该bug备案,其他情况下还是需要尽力定位、修复该bug。
为什么要留在北京工作?为什么选择了北京读研?
主观因素:从小我就有一个梦想,做梦都想去北京,读研三年,在北京生活了三年,我很适应这里,并且喜欢这里。
不过我也很庆幸自己作为学生能来北京生活学习几年,通过读研期间的过渡,让我深深的爱上了这里。
客观因素:
- 气候:北京的气候好。我是一个土生土长的北方人,南方太潮了,冬天太冷了,没有暖气。
- 机会:对于我所所从事的行业,北京的机会更多,视野更广,对自己的发展更好。
为什么不留在北京工作?想要去南方?
主观因素:虽然没来之前一直对首都北京充满着向往,但真正在这里生活了三年才把心中的幻想打破,北京没我想的那么好。
不过我也很庆幸自己作为学生能来北京生活学习几年,因为只有你真的来北京生活过几年,你就会发现,以后无论去任何一个城市,都比在北京幸福。
客观因素:
- 气候:北京的气候不好,甚至沾染了一点恶劣,秋天的时候空气特别干,对皮肤不好。
- 压力:北京的压力大,户口难拿对外地人不友好,不适合生活。南方的长三角经济带,有更多的选择。
你还有什么要问的吗?
您在职场工作的这些年,您觉得在实际工作中最重要的是什么呢?
- 阿里云一面:主要目的围绕业务,帮助业务发展的更好,接口测试,自动化测试,各种测试都是手段,目的是提升产品的质量体系,提升自己的广度和深度。
- 蚂蚁二面:善于反思,善于总结。比如框架很多人只会用却不关心如何实现,框架的优缺点,对待工作的积极主动。这是同样工作的两个人的差距
- 美团优选:学习能力,靠谱。完成好自己的测试工作。多开展专项。
- 美团优选(二面):制定测试设计测试策略,和其他人员的协作,
- 快手:提高测试效率
语言基础
java
jvm
JVM的中文名称叫Java虚拟机,它是由软件技术模拟出计算机运行的一个虚拟的计算机。
JVM也充当着一个翻译官的角色,我们编写出的Java程序,是不能够被操作系统所直接识别的,这时候JVM的作用就体现出来了,它负责把我们的程序翻译给系统“听”,告诉它我们的程序需要做什么操作。
我们都知道Java的代码需要经过编译器,生成.Class文件后,JVM才能识别并运行它,JVM针对每个操作系统开发其对应的解释器,所以只要其操作系统有对应版本的JVM,那么这份Java编译后的代码就能够运行起来,这就是Java能一次编译,到处运行的原因。
JVM的生命周期
JVM在Java程序开始运行的时候,它才运行,程序结束的时它就停止。
一个Java程序会开启一个JVM进程,如果一台机器上运行3个Java程序,那么就会有3个运行中的JVM进程。
JVM中的线程分为两种:守护线程和普通线程
守护线程是JVM自己使用的线程,比如垃圾回收(GC)就是一个守护线程。
普通线程一般是Java程序的线程,只要JVM中有普通线程在执行,那么JVM就不会停止。
结束生命周期
在如下几种情况下,Java虚拟机将结束生命周期
1、执行了System.exit()方法
2、程序正常执行结束
3、程序在执行过程中遇到了异常或错误而终止进程
4、由于操作系统出现错误而导致Java虚拟机进程终止
JDK和JRE的区别
JDK是面向开发人员使用的SDK,它提供了Java的开发环境和运行环境,JDK中包含了JRE。
JRE是Java的运行环境,是面向所有Java程序的使用者,包括开发者。
JVM是包含在JRE里面的。
多线程
什么是进程?什么是线程?
进程是:一个应用程序(1个进程是一个软件)。
线程是:一个进程中的执行场景/执行单元。
注意:一个进程可以启动多个线程。
对于java程序来说,当在DOS命令窗口中输入: java HelloWorld 回车之后。会先启动JVM,而JVM就是一个进程。
JVM再启动一个主线程调用main方法(main方法就是主线程)。 同时再启动一个垃圾回收线程负责看护,回收垃圾。
最起码,现在的java程序中至少有两个线程并发,一个是 垃圾回收线程,一个是 执行main方法的主线程。
进程和线程是什么关系?
进程:可以看做是现实生活当中的公司。
线程:可以看做是公司当中的某个员工。
注意:
进程A和进程B的 内存独立不共享。
魔兽游戏是一个进程,酷狗音乐是一个进程,这两个进程是独立的,不共享资源。、
线程A和线程B是什么关系?
线程A和线程B,堆内存 和 方法区 内存共享。但是 栈内存 独立,一个线程一个栈。
假设启动10个线程,会有10个栈空间,每个栈和每个栈之间,互不干扰,各自执行各自的,这就是多线程并发。 火车站,可以看做是一个进程。火车站中的每一个售票窗口可以看做是一个线程。 我在窗口1购票,你可以在窗口2购票,你不需要等我,我也不需要等你。所以多线程并发可以提高效率。
java中之所以有多线程机制,目的就是为了 提高程序的处理效率。
使用了多线程机制之后,main方法结束,是不是有可能程序也不会结束?
main方法结束只是主线程结束了,主栈空了,其它的栈(线程)可能还在压栈弹栈。
对于单核的CPU来说,真的可以做到真正的多线程并发吗?
对于多核的CPU电脑来说,真正的多线程并发是没问题的。4核CPU表示同一个时间点上,可以真正的有4个进程并发执行。
单核的CPU表示只有一个大脑: 不能够做到真正的多线程并发,但是可以做到给人一种“多线程并发”的感觉。
对于单核的CPU来说,在某一个时间点上实际上只能处理一件事情,但是由于CPU的处理速度极快,多个线程之间频繁切换执行,给别人的感觉是:多个事情同时在做!!!
eg. 线程A:播放音乐
线程B:运行魔兽游戏
线程A和线程B频繁切换执行,人类会感觉音乐一直在播放,游戏一直在运行, 给我们的感觉是同时并发的。(因为计算机的速度很快,我们人的眼睛很慢,所以才会感觉是多线程!)
4、什么是真正的多线程并发?
t1线程执行t1的。
t2线程执行t2的。
t1不会影响t2,t2也不会影响t1。这叫做真正的多线程并发。
5、关于线程对象的生命周期(附图)?
- 新建状态
- 就绪状态
- 运行状态
- 阻塞状态
- 死亡状态
java语言中,实现线程有两种方式
第一种方式:
编写一个类,直接 继承 java.lang.Thread,重写 run方法。
- 怎么创建线程对象? new继承线程的类。
- 怎么启动线程呢? 调用线程对象的
start()方法。
ssm框架
golang
golang:goroutine channel. sync
多线程,多协程
设计模式
MVC设计模式
MVC 是一个设计模式,将应用程序分成三个核心部件:模型(model)– 视图(view)–控制器(controller),它们各自处理自己的任务,实现输入、处理和输出的分离。
1、视图(view)
它是提供给用户的操作界面,是程序的外壳。
2、模型(model)
模型主要负责数据交互。在 MVC 的三个部件中,模型拥有最多的处理任务。一个模型能为多个视图提供数据。
3、控制器(controller)
它负责根据用户从”视图层”输入的指令,选取”模型层”中的数据,然后对其进行相应的操作,产生最终结果。控制器属于管理者角色,从视图接收请求并决定调用哪个模型构件去处理请求,然后再确定用哪个视图来显示模型处理返回的数据。
这三层是紧密联系在一起的,但又是互相独立的,每一层内部的变化不影响其他层。每一层都对外提供接口(Interface),供上面一层调用。
至于这一阶段发生什么?简而言之,首先浏览器发送过来的请求先经过控制器,控制器进行逻辑处理和请求分发,接着会调用模型,这一阶段模型会获取 redis db 以及 MySQL 的数据,获取数据后将渲染好的页面,响应信息会以响应报文的形式返回给客户端,最后浏览器通过渲染引擎将网页呈现在用户面前。
微服务设计模式
微服务适用的的场景: 团队规模较大,超过10人; 业务复杂度高,超过5个以上的子模块(业务功能较复杂); 项目需要长期迭代开发和维护(半年以上)。 微服务优点: 1.服务简单,只关注一个业务功能 2.每个微服务可由不同团队开发 3.微服务是松散耦合的 4.可用不同的编程语言与工具开发 微服务缺点: 1.运维开销大 2.DevOps要求高 3.隐式接口压力大,当某一个服务更改接口格式时,可能涉及到此接口的所有服务都需要做调整。 4.重复劳动 5.分布式系统的复杂性 6.事务、异步、测试面临挑战,跨进程之间的事务、大量的异步处理、多个微服务之间的整体测试都需要有一整套的解决方案,而现在看起来,这些技术并没有成熟。
持续集成
jenkins
Jenkins 是一个开源的实现持续集成的软件工具,能实时监控集成中存在的错误,提供详细的日志文件和提醒功能,还能用图表的形式形象地展示项目构建的趋势和稳定性。
持续集成?
持续集成,Continuous integration ,简称CI。所谓集成测试就是把所有的单元测试跑一遍以及其它一些能自动完成的测试。只有在本地电脑上通过了集成测试的代码才能上传到git服务器上,保证上传的代码没有问题。
- 它是一个自动化的周期性的集成测试过程,从检出代码、编译构建、运行测试、结果记录、测试统计等都是自动完成的,无需人工干预;
- 需要有专门的集成服务器来执行集成构建;
- 需要有代码托管工具支持;
持续集成的作用
- 保证团队开发人员提交代码的质量,减轻了软件发布时的压力;
- 持续集成中的任何一个环节都是自动完成的,无需太多的人工干预,有利于减少重复过程以节省时间、费用和工作量;
持续集成(CI)的流程
该系统的各个组成部分是按如下顺序来发挥作用的:
- 开发者检入代码到源代码仓库。
- CI系统会为每一个项目创建了一个单独的工作区。当预设或请求一次新的构建时,它将把源代码仓库的源码存放到对应的工作区。
- CI系统会在对应的工作区内执行构建过程。
- (配置如果存在)构建完成后,CI系统会在一个新的构件中执行定义的一套测试。完成后触发通知(Email,RSS等等)给相关的当事人。
- (配置如果存在)如果构建成功,这个构件会被打包并转移到一个部署目标(如应用服务器)或存储为软件仓库中的一个新版本。软件仓库可以是CI系统的一部分,也可以是一个外部的仓库,诸如一个文件服务器或者像Java.net、SourceForge之类的网站。
- CI系统通常会根据请求发起相应的操作,诸如即时构建、生成报告,或者检索一些构建好的构件。
数据库
关系型数据库(SQL)
关系型数据库指的是使用关系模型(二维表格模型)来组织数据的数据库。
关系模型可以简单理解为二维表格模型,而一个关系型数据库就是由二维表及其之间的关系组成的一个数据组织。
优点
- 采用二维表结构非常贴近正常开发逻辑(关系型数据模型相对层次型数据模型和网状型数据模型等其他模型来说更容易理解);
- 支持通用的SQL(结构化查询语言)语句;
- 丰富的完整性大大减少了数据冗余和数据不一致的问题。并且全部由表结构组成,文件格式一致;
- 可以用SQL句子多个表之间做非常繁杂的查询;
- 关系型数据库提供对事务的支持,能保证系统中事务的正确执行,同时提供事务的恢复、回滚、并发控制和死锁问题的解决。
- 数据存储在磁盘中,安全可靠。
缺点
随着互联网企业的不断发展,数据日益增多,因此关系型数据库面对海量的数据会存在很多的不足。
- 高并发读写能力差:网站类用户的并发性访问非常高,而一台数据库的最大连接数有限,且硬盘 I/O 有限,不能满足很多人同时连接。
- 海量数据情况下读写效率低:对大数据量的表进行读写操作时,需要等待较长的时间等待响应。
- 可扩展性不足:不像web server和app server那样简单的添加硬件和服务节点来拓展性能和负荷工作能力。
- 数据模型灵活度低:关系型数据库的数据模型定义严格,无法快速容纳新的数据类型(需要提前知道需要存储什么样类型的数据)。
非关系型数据库(NOSQL)
非关系型数据库又被称为 NoSQL(Not Only SQL ),意为不仅仅是 SQL。通常指数据以对象的形式存储在数据库中,而对象之间的关系通过每个对象自身的属性来决定,常用于存储非结构化的数据。
优点
- 非关系型数据库存储数据的格式可以是 key-value 形式、文档形式、图片形式等。使用灵活,应用场景广泛,而关系型数据库则只支持基础类型。
- 速度快,效率高。 NoSQL 可以使用硬盘或者随机存储器作为载体,而关系型数据库只能使用硬盘。
- 海量数据的维护和处理非常轻松,成本低。
- 非关系型数据库具有扩展简单、高并发、高稳定性、成本低廉的优势。
- 可以实现数据的分布式处理。
缺点
- 非关系型数据库暂时不提供 SQL 支持,学习和使用成本较高。
- 非关系数据库没有事务处理,无法保证数据的完整性和安全性。适合处理海量数据,但是不一定安全。
- 功能没有关系型数据库完善。
- 复杂表关联查询不容易实现。
redis数据类型
Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(无序集合)及zset(有序集合)。
String
-
Sring是redis中最基本的数据类型,一个key对应一个value。String类型是二进制安全的,意思是 redis 的 string 可以包含任何数据。如数字,字符串,jpg图片或者序列化的对象。在
Redis中String是可以修改的,称为动态字符串(Simple Dynamic String简称SDS)(快拿小本本记名词,要考的),说是字符串但它的内部结构更像是一个ArrayList,内部维护着一个字节数组,并且在其内部预分配了一定的空间,以减少内存的频繁分配。 -
Redis的内存分配机制是这样:- 当字符串的长度小于 1MB时,每次扩容都是加倍现有的空间。
- 如果字符串长度超过 1MB时,每次扩容时只会扩展 1MB 的空间。
这样既保证了内存空间够用,还不至于造成内存的浪费,字符串最大长度为 512MB。
-
使用:get 、 set 、 del 、 incr、 decr 等。
-
实战场景:
- 1.缓存: 经典使用场景,把常用信息,字符串,图片或者视频等信息放到redis中,redis作为缓存层,mysql做持久化层,降低mysql的读写压力。
- 2.计数器:redis是单线程模型,一个命令执行完才会执行下一个,同时数据可以一步落地到其他的数据源。
- 3.session:常见方案spring session + redis实现session共享,
-
本质是c语言的字符数组,加上了一点别的标识属性的结构体,优点:字符串唱出的获取从o(n)降到o1;减少字符串扩容引起的数据搬运次数;可以储存更复杂的二进制数据
hash
- Hash:是一个Mapmap,指值本身又是一种键值对结构
- 使用:所有hash的命令都是 h 开头的 hget 、hset 、 hdel 等
- 实战场景:
- 1.缓存: 能直观,相比string更节省空间,的维护缓存信息,如用户信息,视频信息等。
list
- List 说白了就是链表(redis 使用双端链表实现的 List),是有序的,value可以重复,可以通过下标取出对应的value值,左右两边都能进行插入和删除数据。
- 使用列表的技巧
- lpush+lpop=Stack(栈)
- lpush+rpop=Queue(队列)
- lpush+ltrim=Capped Collection(有限集合)
- lpush+brpop=Message Queue(消息队列)
- 实战场景:
- 1.timeline:例如微博的时间轴,有人发布微博,用lpush加入时间轴,展示新的列表信息。
set
- Set:集合类型也是用来保存多个字符串的元素,但和列表不同的是集合中 1. 不允许有重复的元素,2.集合中的元素是无序的,不能通过索引下标获取元素,3.支持集合间的操作,可以取多个集合取交集、并集、差集。
- 使用:命令都是以s开头的 sset 、srem、scard、smembers、sismember
- 实战场景;
- 1.标签(tag),给用户添加标签,或者用户给消息添加标签,这样有同一标签或者类似标签的可以给推荐关注的事或者关注的人。
- 2.点赞,或点踩,收藏等,可以放到set中实现
zset
- 有序集合和集合有着必然的联系,保留了集合不能有重复成员的特性,区别是,有序集合中的元素是可以排序的,它给每个元素设置一个分数,作为排序的依据。(有序集合中的元素不可以重复,但是score 分数 可以重复,就和一个班里的同学学号不能重复,但考试成绩可以相同)。
-
使用: 有序集合的命令都是 以 z 开头 zadd 、 zrange、 zscore
- 实战场景:
- 1.排行榜:有序集合经典使用场景。例如小说视频等网站需要对用户上传的小说视频做排行榜,榜单可以按照用户关注数,更新时间,字数等打分,做排行。
redis为什么快
- 基于内存实现,Redis是基于内存存储实现的数据库,相对于数据存在磁盘的数据库,就省去磁盘磁盘I/O的消耗。MySQL等磁盘数据库,需要建立索引来加快查询效率,而Redis数据存放在内存,直接操作内存,所以就很快。
- 高效的数据结构,我们知道,MySQL索引为了提高效率,选择了B+树的数据结构。其实合理的数据结构,就是可以让你的应用/程序更快。
- 合理的数据编码,Redis支持多种数据基本类型,每种基本类型对应不同的数据结构,每种数据结构对应不一样的编码。为了提高性能,Redis设计者总结出,数据结构最适合的编码搭配。
- 合理的线程模型,单线程
- 虚拟内存机制,Redis直接自己构建了VM机制 ,不会像一般的系统会调用系统函数处理,会浪费一定的时间去移动和请求。虚拟内存机制就是暂时把不经常访问的数据(冷数据)从内存交换到磁盘中,从而腾出宝贵的内存空间用于其它需要访问的数据(热数据)。通过VM功能可以实现冷热数据分离,使热数据仍在内存中、冷数据保存到磁盘。这样就可以避免因为内存不足而造成访问速度下降的问题。
Redis为什么是单线程的?
Redis官方很敷衍就随便给了一点解释。不过基本要点也都说了,因为Redis的瓶颈不是cpu的运行速度,而往往是网络带宽和机器的内存大小。再说了,单线程切换开销小,容易实现既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了。
大家所熟知的 Redis 确实是单线程模型,指的是执行 Redis 命令的核心模块是单线程的,而不是整个 Redis 实例就一个线程,Redis 其他模块还有各自模块的线程的。
Redis 不仅仅是单线程
一般来说 Redis 的瓶颈并不在 CPU,而在内存和网络。如果要使用 CPU 多核,可以搭建多个 Redis 实例来解决。
其实,Redis 4.0 开始就有多线程的概念了,比如 Redis 通过多线程方式在后台删除对象、以及通过 Redis 模块实现的阻塞命令等。
这个 Theaded IO 指的是在网络 IO 处理方面上了多线程,如网络数据的读写和协议解析等,需要注意的是,执行命令的核心模块还是单线程的。
为什么网络处理要引入多线程?
Redis 的瓶颈并不在 CPU,而在内存和网络。
内存不够的话,可以加内存或者做数据结构优化和其他优化等,但网络的性能优化才是大头,网络 IO 的读写在 Redis 整个执行期间占用了大部分的 CPU 时间,如果把网络处理这部分做成多线程处理方式,那对整个 Redis 的性能会有很大的提升。
如果万一CPU成为你的Redis瓶颈了,或者,你就是不想让服务器其他核闲置,那怎么办?
那也很简单,你多起几个Redis进程就好了。Redis是keyvalue数据库,又不是关系数据库,数据之间没有约束。只要客户端分清哪些key放在哪个Redis进程上就可以了。redis-cluster可以帮你做的更好。
单线程可以处理高并发请求吗?
当然可以了,Redis都实现了。有一点概念需要澄清,并发并不是并行。 (相关概念:并发性I/O流,意味着能够让一个计算单元来处理来自多个客户端的流请求。并行性,意味着服务器能够同时执行几个事情,具有多个计算单元)
我们使用单线程的方式是无法发挥多核CPU 性能,有什么办法发挥多核CPU的性能嘛?
我们可以通过在单机开多个Redis 实例来完善! 警告:这里我们一直在强调的单线程,只是在处理我们的网络请求的时候只有一个线程来处理,一个正式的Redis Server运行的时候肯定是不止一个线程的,这里需要大家明确的注意一下! 例如Redis进行持久化的时候会以子进程或者子线程的方式执行(具体是子线程还是子进程待读者深入研究)
简述Redis的数据淘汰机制
volatile-lru 从已设置过期时间的数据集中挑选最近最少使用的数据淘汰 volatile-ttl 从已设置过期时间的数据集中挑选将要过期的数据淘汰 volatile-random从已设置过期时间的数据集中任意选择数据淘汰 allkeys-lru从所有数据集中挑选最近最少使用的数据淘汰 allkeys-random从所有数据集中任意选择数据进行淘汰 noeviction禁止驱逐数据
Redis怎样防止异常数据不丢失?
RDB 持久化 将某个时间点的所有数据都存放到硬盘上。 可以将快照复制到其它服务器从而创建具有相同数据的服务器副本。 如果系统发生故障,将会丢失最后一次创建快照之后的数据。 如果数据量很大,保存快照的时间会很长。 AOF 持久化 将写命令添加到 AOF 文件(Append Only File)的末尾。 使用 AOF 持久化需要设置同步选项,从而确保写命令同步到磁盘文件上的时机。这是因为对文件进行写入并不会马上将内容同步到磁盘上,而是先存储到缓冲区,然后由操作系统决定什么时候同步到磁盘。有以下同步选项: 选项同步频率always每个写命令都同步everysec每秒同步一次no让操作系统来决定何时同步 always 选项会严重减低服务器的性能; everysec 选项比较合适,可以保证系统崩溃时只会丢失一秒左右的数据,并且 Redis 每秒执行一次同步对服务器性能几乎没有任何影响; no 选项并不能给服务器性能带来多大的提升,而且也会增加系统崩溃时数据丢失的数量 随着服务器写请求的增多,AOF 文件会越来越大。Redis 提供了一种将 AOF 重写的特性,能够去除 AOF 文件中的冗余写命令。
缓存穿透,缓存雪崩以及缓存击穿
缓存穿透:就是客户持续向服务器发起对不存在服务器中数据的请求。客户先在Redis中查询,查询不到后去数据库中查询。 缓存击穿:就是一个很热门的数据,突然失效,大量请求到服务器数据库中 缓存雪崩:就是大量数据同一时间失效。 打个比方,你是个很有钱的人,开满了百度云,腾讯视频各种杂七杂八的会员,但是你就是没有netflix的会员,然后你把这些账号和密码发布到一个你自己做的网站上,然后你有一个朋友每过十秒钟就查询你的网站,发现你的网站没有Netflix的会员后打电话向你要。你就相当于是个数据库,网站就是Redis。这就是缓存穿透。 大家都喜欢看腾讯视频上的《水果传》,但是你的会员突然到期了,大家在你的网站上看不到腾讯视频的账号,纷纷打电话向你询问,这就是缓存击穿 你的各种会员突然同一时间都失效了,那这就是缓存雪崩了。
放心,肯定有办法解决的。 缓存穿透: 1.接口层增加校验,对传参进行个校验,比如说我们的id是从1开始的,那么id<=0的直接拦截; 2.缓存中取不到的数据,在数据库中也没有取到,这时可以将key-value对写为key-null,这样可以防止攻击用户反复用同一个id暴力攻击 缓存击穿: 最好的办法就是设置热点数据永不过期,拿到刚才的比方里,那就是你买腾讯一个永久会员 缓存雪崩: 1.缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。 2.如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中。
Redis中的Master-Slave模式
连接过程
- 主服务器创建快照文件,发送给从服务器,并在发送期间使用缓冲区记录执行的写命令。快照文件发送完毕之后,开始向从服务器发送存储在缓冲区中的写命令;
- 从服务器丢弃所有旧数据,载入主服务器发来的快照文件,之后从服务器开始接受主服务器发来的写命令;
- 主服务器每执行一次写命令,就向从服务器发送相同的写命令。
主从链
随着负载不断上升,主服务器可能无法很快地更新所有从服务器,或者重新连接和重新同步从服务器将导致系统超载。为了解决这个问题,可以创建一个中间层来分担主服务器的复制工作。中间层的服务器是最上层服务器的从服务器,又是最下层服务器的主服务器。

Sentinel(哨兵)可以监听集群中的服务器,并在主服务器进入下线状态时,自动从从服务器中选举出新的主服务器。
分片
分片是将数据划分为多个部分的方法,可以将数据存储到多台机器里面,这种方法在解决某些问题时可以获得线性级别的性能提升。 假设有 4 个 Redis 实例 R0,R1,R2,R3,还有很多表示用户的键 user:1,user:2,… ,有不同的方式来选择一个指定的键存储在哪个实例中。
最简单的方式是范围分片,例如用户 id 从 0~1000 的存储到实例 R0 中,用户 id 从 1001~2000 的存储到实例 R1 中,等等。但是这样需要维护一张映射范围表,维护操作代价很高。 还有一种方式是哈希分片,使用 CRC32 哈希函数将键转换为一个数字,再对实例数量求模就能知道应该存储的实例。
根据执行分片的位置,可以分为三种分片方式: 客户端分片:客户端使用一致性哈希等算法决定键应当分布到哪个节点。 代理分片:将客户端请求发送到代理上,由代理转发请求到正确的节点上。 服务器分片:Redis Cluster
数据设计的分库分表,考虑哪些因素?
-
事务问题
- 方案一:使用分布式事务
- 优点:交由数据库管理,简单有效
- 缺点:性能代价高,特别是shard越来越多时
- 方案二:由应用程序和数据库共同控制
- 原理:将一个跨多个数据库的分布式事务分拆成多个仅处 于单个数据库上面的小事务,并通过应用程序来总控 各个小事务。
- 优点:性能上有优势
- 缺点:需要应用程序在事务控制上做灵活设计。如果使用 了spring的事务管理,改动起来会面临一定的困难。
-
跨界点jion
-
只要是进行切分,跨节点Join的问题是不可避免的。但是良好的设计和切分却可以减少此类情况的发生。解决这一问题的普遍做法是分两次查询实现。在第一次查询的结果集中找出关联数据的id,根据这些id发起第二次请求得到关联数据。
-
-
数据迁移,容量规划,扩容等问题
- 来自淘宝综合业务平台团队,它利用对2的倍数取余具有向前兼容的特性(如对4取余得1的数对2取余也是1)来分配数据,避免了行级别的数据迁移,但是依然需要进行表级别的迁移,同时对扩容规模和分表数量都有限制。总得来说,这些方案都不是十分的理想,多多少少都存在一些缺点,这也从一个侧面反映出了Sharding扩容的难度。
-
跨节点的count,order by,group by以及聚合函数问题
-
这些是一类问题,因为它们都需要基于全部数据集合进行计算。多数的代理都不会自动处理合并工作。解决方案:与解决跨节点join问题的类似,分别在各个节点上得到结果后在应用程序端进行合并。和join不同的是每个结点的查询可以并行执行,因此很多时候它的速度要比单一大表快很多。但如果结果集很大,对应用程序内存的消耗是一个问题。
-
数据库主键和外键
主键是能确定一条记录的唯一标识,比如,一条记录包括身份正号,姓名,年龄。
外键用于与另一张表的关联。是能确定另一张表记录的字段,用于保持数据的一致性。
比如,A表中的一个字段,是B表的主键,那他就可以是A表的外键。
主键、外键和索引的区别?
| 主键 | 外键 | 索引 | |
|---|---|---|---|
| 定义: | 唯一标识一条记录,不能有重复的,不允许为空 | 表的外键是另一表的主键, 外键可以有重复的, 可以是空值 | 该字段没有重复值,但可以有一个空值 |
| 作用: | 用来保证数据完整性 | 用来和其他表建立联系用的 | 是提高查询排序的速度 |
| 个数: | 主键只能有一个 | 一个表可以有多个外键 | 一个表可以有多个惟一索引 |
索引
数据库中索引的作用是用来加快查找速度,原理是将表中建立索引列的数据独立出来用特殊的数据结构存储,(如B-Tree,Hash),数据库实现通常使用B树和B+树。索引相当于字典的目录,可以通过查找目录来得到我们所需要的数据所在的位置,而不需要翻整本字典.
使用索引需要注意的问题
索引会带来额外的开销,额外的存储空间,额外的创建时间,额外维护时间,所以要选择适合的情况去建立索引
索引的类型
-
普通索引:普通索引允许被索引的数据列包含重复的值。
-
唯一索引:被索引包含的数据列不允许有相同的值, 可以包含null
-
主键索引:主键创建的索引,唯一且不能为空,
-
全文索引:通过关键字的匹配来进行查询过滤,那么就需要基于相似度的查询,而不是原来的精确数值比较。比 like + % 快 N 倍https://blog.csdn.net/mrzhouxiaofei/article/details/79940958
-
聚集索引(一级索引) : 该索引中键值的逻辑顺序决定了表中相应行的物理顺序。 (比如字典的按照拼音查询 逻辑顺序和物理顺序一致),一个表中只能有一个聚集索引
-
非聚集索引(二级索引) : 该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同。(比如字典中的按部首查询 一个字可能在54页有可能在554页)(mysql中没有)
例子:比如查字典,通过拼音查某个字,这个字所在页数上下都是那个拼音,这个正文本身 就按照一定规则排序,就叫做聚集索引;然后按照部首查字典,查到某一个的该字后, 你发现这个字的上下并不都是那个部首,这种目录纯粹是目录,正文纯粹是正文的情况 叫做非聚集索引。
- 主键作为聚集索引,是一种极大的浪费;虽然sql server将主键作为默认的聚集索引;但是选择恰当的字段作为聚集索引,会极大的提升数据库的效率。聚集索引要求的:“既不能绝大多数都相同,又不能只有极少数相同”的规则
适合建立索引的字段
经常搜索
经常排序
经常跟在Where语句后面
数据类型小
简单数据类型
列中尽量避免null
索引是用来优化数据库的查找效率用的。
聚集索引和非聚集索引的区别?
聚集索引一定是唯一索引。但唯一索引不一定是聚集索引。
聚集索引,在索引页里直接存放数据,而非聚集索引在索引页里存放的是索引,这些索引指向专门的数据页的数据。
MySQL存储引擎
MyISAM和InnoDB 简单总结
1) 事务支持 MyISAM不支持事务,而InnoDB支持。InnoDB的AUTOCOMMIT默认是打开的,即每条SQL语句会默认被封装成一个事务,自动提交,这样会影响速度,所以最好是把多条SQL语句显示放在begin和commit之间,组成一个事务去提交。
MyISAM是非事务安全型的,而InnoDB是事务安全型的,默认开启自动提交,宜合并事务,一同提交,减小数据库多次提交导致的开销,大大提高性能。
2) 存储结构 MyISAM:每个MyISAM在磁盘上存储成三个文件。第一个文件的名字以表的名字开始,扩展名指出文件类型。.frm文件存储表定义。数据文件的扩展名为.MYD (MYData)。索引文件的扩展名是.MYI (MYIndex)。 InnoDB:所有的表都保存在同一个数据文件中(也可能是多个文件,或者是独立的表空间文件),InnoDB表的大小只受限于操作系统文件的大小,一般为2GB。
3) 存储空间 MyISAM:可被压缩,存储空间较小。支持三种不同的存储格式:静态表(默认,但是注意数据末尾不能有空格,会被去掉)、动态表、压缩表。 InnoDB:需要更多的内存和存储,它会在主内存中建立其专用的缓冲池用于高速缓冲数据和索引。
4) 可移植性、备份及恢复 MyISAM:数据是以文件的形式存储,所以在跨平台的数据转移中会很方便。在备份和恢复时可单独针对某个表进行操作。 InnoDB:免费的方案可以是拷贝数据文件、备份 binlog,或者用 mysqldump,在数据量达到几十G的时候就相对痛苦了。
5) 事务支持 MyISAM:强调的是性能,每次查询具有原子性,其执行数度比InnoDB类型更快,但是不提供事务支持。 InnoDB:提供事务支持事务,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
6) AUTO_INCREMENT MyISAM:可以和其他字段一起建立联合索引。引擎的自动增长列必须是索引,如果是组合索引,自动增长可以不是第一列,他可以根据前面几列进行排序后递增。 InnoDB:InnoDB中必须包含只有该字段的索引。引擎的自动增长列必须是索引,如果是组合索引也必须是组合索引的第一列。
7) 表锁差异 MyISAM:只支持表级锁,用户在操作myisam表时,select,update,delete,insert语句都会给表自动加锁,如果加锁以后的表满足insert并发的情况下,可以在表的尾部插入新的数据。 InnoDB:支持事务和行级锁,是innodb的最大特色。行锁大幅度提高了多用户并发操作的新能。但是InnoDB的行锁,只是在WHERE的主键是有效的,非主键的WHERE都会锁全表的。
MyISAM锁的粒度是表级,而InnoDB支持行级锁定。简单来说就是, InnoDB支持数据行锁定,而MyISAM不支持行锁定,只支持锁定整个表。即MyISAM同一个表上的读锁和写锁是互斥的,MyISAM并发读写时如果等待队列中既有读请求又有写请求,默认写请求的优先级高,即使读请求先到,所以MyISAM不适合于有大量查询和修改并存的情况,那样查询进程会长时间阻塞。因为MyISAM是锁表,所以某项读操作比较耗时会使其他写进程饿死。
8) 全文索引 MyISAM:支持(FULLTEXT类型的)全文索引 InnoDB:不支持(FULLTEXT类型的)全文索引,但是innodb可以使用sphinx插件支持全文索引,并且效果更好。
全文索引是指对char、varchar和text中的每个词(停用词除外)建立倒排序索引。MyISAM的全文索引其实没啥用,因为它不支持中文分词,必须由使用者分词后加入空格再写到数据表里,而且少于4个汉字的词会和停用词一样被忽略掉。
另外,MyIsam索引和数据分离,InnoDB在一起,MyIsam天生非聚簇索引,最多有一个unique的性质,InnoDB的数据文件本身就是主键索引文件,这样的索引被称为“聚簇索引”
9) 表主键 MyISAM:允许没有任何索引和主键的表存在,索引都是保存行的地址。 InnoDB:如果没有设定主键或者非空唯一索引,就会自动生成一个6字节的主键(用户不可见),数据是主索引的一部分,附加索引保存的是主索引的值。InnoDB的主键范围更大,最大是MyISAM的2倍。
10) 表的具体行数 MyISAM:保存有表的总行数,如果select count() from table;会直接取出出该值。 InnoDB:没有保存表的总行数(只能遍历),如果使用select count() from table;就会遍历整个表,消耗相当大,但是在加了wehre条件后,myisam和innodb处理的方式都一样。
11) CURD操作 MyISAM:如果执行大量的SELECT,MyISAM是更好的选择。 InnoDB:如果你的数据执行大量的INSERT或UPDATE,出于性能方面的考虑,应该使用InnoDB表。DELETE 从性能上InnoDB更优,但DELETE FROM table时,InnoDB不会重新建立表,而是一行一行的删除,在innodb上如果要清空保存有大量数据的表,最好使用truncate table这个命令。
12) 外键 MyISAM:不支持 InnoDB:支持
MyISAM和InnoDB两者的应用场景: 1) MyISAM管理非事务表。它提供高速存储和检索,以及全文搜索能力。如果应用中需要执行大量的SELECT查询,那么MyISAM是更好的选择。 2) InnoDB用于事务处理应用程序,具有众多特性,包括ACID事务支持。如果应用中需要执行大量的INSERT或UPDATE操作,则应该使用InnoDB,这样可以提高多用户并发操作的性能。
但是实际场景中,针对具体问题需要具体分析,一般而言可以遵循以下几个问题: - 数据库是否有外键? - 是否需要事务支持? - 是否需要全文索引? - 数据库经常使用什么样的查询模式?在写多读少的应用中还是Innodb插入性能更稳定,在并发情况下也能基本,如果是对读取速度要求比较快的应用还是选MyISAM。 - 数据库的数据有多大? 大尺寸倾向于innodb,因为事务日志,故障恢复。
innodb引擎的四大特性
- 插入缓冲:高写性能
- 二次写:提高可靠性
- 自适应哈希索引
- 预读
- 线性预读
- 随机预读
checkpoint机制
思考一下这个场景:如果重做日志可以无限地增大,同时缓冲池也足够大,那么是不需要将缓冲池中页的新版本刷新回磁盘。因为当发生宕机时,完全可以通过重做日志来恢复整个数据库系统中的数据到宕机发生的时刻。
但是这需要两个前提条件:1、缓冲池可以缓存数据库中所有的数据;2、重做日志可以无限增大
因此Checkpoint(检查点)技术就诞生了,目的是解决以下几个问题:1、缩短数据库的恢复时间;2、缓冲池不够用时,将脏页刷新到磁盘;3、重做日志不可用时,刷新脏页。
当数据库发生宕机时,数据库不需要重做所有的日志,因为Checkpoint之前的页都已经刷新回磁盘。数据库只需对Checkpoint后的重做日志进行恢复,这样就大大缩短了恢复的时间。
当缓冲池不够用时,根据LRU算法会溢出最近最少使用的页,若此页为脏页,那么需要强制执行Checkpoint,将脏页也就是页的新版本刷回磁盘。
当重做日志出现不可用时,因为当前事务数据库系统对重做日志的设计都是循环使用的,并不是让其无限增大的,重做日志可以被重用的部分是指这些重做日志已经不再需要,当数据库发生宕机时,数据库恢复操作不需要这部分的重做日志,因此这部分就可以被覆盖重用。如果重做日志还需要使用,那么必须强制Checkpoint,将缓冲池中的页至少刷新到当前重做日志的位置。
事务
总的来说,事务就是在数据库增删查改的过程中,保证数据的正确和安全。
过程中可能会产生以下的问题 a.事务给a账户+1亿元,b账户-1亿元,如果这个事务崩溃,就要进行事务回滚保证数据正确。 需要原子性来保证。 c.只有合法的数据(按照关系约束和函数约束)才能写入数据库 i.事务t1修改a的数据,此时事务t2来读取a的数据,但是后来事务a失败,导致了回滚,此时事务2读到的是脏数据。需要隔离性 d.事务给数据库写入数据的时候,崩溃了,要保证或者写入磁盘,或者回滚。需要持久性
对应事务的四个特性 a.原子性:事务要么完成要么取消。 c.一致性:合法数据不会凭空取消产生,依赖于原子性和隔离性。 i.隔离形:不论事务t1,t2谁先完成,最后必须保持数据只有一种可能 d.持久性:如果事务刚刚提交,就崩溃了,数据会保存在数据库中。
由于并发会导致一些异常,所以事务隔离级别,快速理解脏读、不可重复读、幻读。
事务隔离级别
有四种隔离级别,分别是读未提交(Read uncommitted),读已提交(Read committed),可重复读(Repeatable read),可串行化(Serializable),用来解决数据库操作中产生的各种问题。
一、读未提交(Read uncommitted) 在这种隔离级别下,所有事务能够读取其他事务未提交的数据。读取其他事务未提交的数据,会造成脏读。因此在该种隔离级别下,不能解决脏读、不可重复读和幻读。
读未提交可能会产生脏读的现象,那么怎么解决脏读呢?那就是使用读已提交。
加锁范围:不加锁。
未提交读:什么都不保证。
二、读已提交(Read committed) 在这种隔离级别下,只能读取到已经提交的数据,可以避免脏读。已提交读不能保证可重复读,也就是说,前后两次读取,会获取到不同的结果集。这里的不同结果集可能包含两种情况:
1,结果集行数不一致,insert和delete导致的。(幻读)
2,结果集中的某些记录不一致,update导致的。(不可重复读)
注意【1】这是大多数数据库系统默认的隔离级别,MySQL的默认隔离级别:可重复读。Oracle的默认隔离级别:已提交读。DB2的默认隔离级别:已提交读。
加锁范围:行锁,只锁修改的行。比如我的update语句只修改一行记录,那么只锁这一行。
读已提交能够保证:我修改的10条数据,在我这个事务中,不会被其他事务改变。
读已提交不能保证:我读取的100条数据,在我这个事务中始终不变。
三、可重复读(Repeatable read)
可重复读 (repeatable read):可重复读。在同一个事务内的查询都是事务开始时刻一致的,InnoDB默认级别。会出现幻读的情况,所谓的幻读,就是前后两次读取到的记录行数不一致。事务A在读取某些记录时,事务B又在事务A内插入了一条新记录,当事务A再次读取该范围的记录时,发现前后两次读取的结果集不是完全一致。
注意,这里有一个关键点:2次读取都是在同一个事务中!也就是说,可重复读指的是同一个事务中的读出来的数据是可以保证不被其他事务改变。
加锁范围:行锁,锁定所有查询的行。这里我个人理解是锁定返回结果集,也就是说我读取的这部分数据,其他事务是不能修改的。但是我再次读取的时候,结果集可能会发生变化。
可重复读能够保证:我读取的100条数据,在我这个事务中始终不变。
可重复读不能够保证:同一个查询语句,在同一个事务中,始终查询到100条记录。
可重复读依然会产生幻读的现象,此时我们可以使用串行化来解决。
四、可串行化(Serializable) 在这种隔离级别下,所有的事务顺序执行,所以他们之间不存在冲突,从而能有效地解决脏读、不可重复读和幻读的现象。但是安全和效率不能兼得,这样事务隔离级别,会导致大量的操作超时和锁竞争,从而大大降低数据库的性能,一般不使用这样事务隔离级别。
加锁范围:锁表。
下面用一张表格来表示他们能够解决的问题
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交(Read uncommitted) | ×(未解决) | × | × |
| 读已提交(Read committed) | √(解决) | × | × |
| 可重复读(Repeatable read) | √ | √ | × |
| 可串行化(Serializable) | √ | √ | √ |
当然,以上的内容是一种规范,不同的数据库厂商可以有不同的实现。例如在mysql的可重复读的级别上,使用间隙锁的方式就已经解决了幻读的问题。
脏读(读取未提交数据)
A事务读取B事务尚未提交的数据,此时如果B事务发生错误并执行回滚操作,那么A事务读取到的数据就是脏数据。就好像原本的数据比较干净、纯粹,此时由于B事务更改了它,这个数据变得不再纯粹。这个时候A事务立即读取了这个脏数据,但事务B良心发现,又用回滚把数据恢复成原来干净、纯粹的样子,而事务A却什么都不知道,最终结果就是事务A读取了此次的脏数据,称为脏读。
| 时间顺序 | 转账事务 | 取款事务 |
|---|---|---|
| 1 | 开始事务 | |
| 2 | 开始事务 | |
| 3 | 查询账户余额为2000元 | |
| 4 | 取款1000元,余额被更改为1000元 | |
| 5 | 查询账户余额为1000元(产生脏读) | |
| 6 | 取款操作发生未知错误,事务回滚,余额变更为2000元 | |
| 7 | 转入2000元,余额被更改为3000元(脏读的1000+2000) | |
| 8 | 提交事务 | |
| 备注 | 按照正确逻辑,此时账户余额应该为4000元 |
不可重复读(前后多次读取,数据内容不一致)
事务A在执行读取操作,由整个事务A比较大,前后读取同一条数据需要经历很长的时间 。而在事务A第一次读取数据,比如此时读取了小明的年龄为20岁,事务B执行更改操作,将小明的年龄更改为30岁,此时事务A第二次读取到小明的年龄时,发现其年龄是30岁,和之前的数据不一样了,也就是数据不重复了,系统不可以读取到重复的数据,成为不可重复读。
| 时间顺序 | 事务A | 事务B |
|---|---|---|
| 1 | 开始事务 | |
| 2 | 第一次查询,小明的年龄为20岁 | |
| 3 | 开始事务 | |
| 4 | 其他操作 | |
| 5 | 更改小明的年龄为30岁 | |
| 6 | 提交事务 | |
| 7 | 第二次查询,小明的年龄为30岁 | |
| 备注 | 按照正确逻辑,事务A前后两次读取到的数据应该一致 |
幻读(前后多次读取,数据总量不一致)
事务A在执行读取操作,需要两次统计数据的总量,前一次查询数据总量后,此时事务B执行了新增数据的操作并提交后,这个时候事务A读取的数据总量和之前统计的不一样,就像产生了幻觉一样,平白无故的多了几条数据,成为幻读。
| 时间顺序 | 事务A | 事务B |
|---|---|---|
| 1 | 开始事务 | |
| 2 | 第一次查询,数据总量为100条 | |
| 3 | 开始事务 | |
| 4 | 其他操作 | |
| 5 | 新增100条数据 | |
| 6 | 提交事务 | |
| 7 | 第二次查询,数据总量为200条 | |
| 备注 | 按照正确逻辑,事务A前后两次读取到的数据总量应该一致 |
MySQL 加锁处理分析
简述关系型数据库与非关系形数据库(nosql)的区别与联系
关系型数据库:指采用了关系模型来组织数据的数据库。 关系模型指的就是二维表格模型,而一个关系型数据库就是由二维表及其之间的联系所组成的一个数据组织。
1.成本:Nosql数据库简单易部署,基本都是开源软件,不需要像使用Oracle那样花费大量成本购买使用,相比关系型数据库价格便宜。 2.查询速度:Nosql数据库将数据存储于缓存之中,而且不需要经过SQL层的解析,关系型数据库将数据存储在硬盘中,自然查询速度远不及Nosql数据库。 3.存储数据的格式:Nosql的存储格式是key,value形式、文档形式、图片形式等等,所以可以存储基础类型以及对象或者是集合等各种格式,而数据库则只支持基础类型。 4.扩展性:关系型数据库有类似join这样的多表查询机制的限制导致扩展很艰难。Nosql基于键值对,数据之间没有耦合性,所以非常容易水平扩展。 5.持久存储:Nosql不使用于持久存储,海量数据的持久存储,还是需要关系型数据库 6.数据一致性:非关系型数据库一般强调的是数据最终一致性,不像关系型数据库一样强调数据的强一致性,从非关系型数据库中读到的有可能还是处于一个中间态的数据, Nosql不提供对事务的处理。
数据库的事务
事务是应用程序中一系列严密的操作,所有操作必须成功完成,否则在每个操作中所作的所有更改都会被撤消。也就是事务具有原子性,一个事务中的一系列的操作要么全部成功,要么一个都不做。 事务的结束有两种,当事务中的所以步骤全部成功执行时,事务提交。如果其中一个步骤失败,将发生回滚操作,撤消撤消之前到事务开始时的所以操作。
事务是恢复和并发控制的基本单位。
事务ACID属性
事务应该具有4个属性:原子性、一致性、隔离性、持久性。这四个属性通常称为ACID特性。
原子性(atomicity):一个事务是一个不可分割的工作单位,事务中包括的操作要么都做,要么都不做。
一致性(consistency):事务必须是使数据库从一个一致性状态变到另一个一致性状态。一致性与原子性是密切相关的。
隔离性(isolation):一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
持久性(durability):持久性也称永久性(permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响。
分布式事务
分布式事务、事务隔离级别、ACID我相信大家这些东西都耳熟能详了,那什么是事务呢?
概念:一般是指要做的或所做的事情。
在计算机术语中是指访问并可能更新数据库中各种数据项的一个程序执行单元(unit)。
事务通常由高级数据库操纵语言或编程语言(如SQL,C++或Java)书写的用户程序用户程序的执行所引起,并用形如begin transaction和end transaction语句(或函数调用)来界定。
事务由事务开始(begin transaction)和事务结束(end transaction)之间执行的全体操作组成
我接触和了解到的分布式事务大概分为:
- 2pc(两段式提交)
- 3pc(三段式提交)
- TCC(Try、Confirm、Cancel)
- 最大努力通知
- XA
- 本地消息表(ebay研发出的)
- 半消息/最终一致性(RocketMQ)
这里我就介绍下最简单的2pc(两段式),以及大家以后可能比较常用的半消息事务也就是最终一致性,目的是让大家理解下分布式事务里面消息中间件的作用,别的事务都大同小异,都有很多优点。
2pc(两段式提交) :

2pc(两段式提交)可以说是分布式事务的最开始的样子了,像极了媒婆,就是通过消息中间件协调多个系统,在两个系统操作事务的时候都锁定资源但是不提交事务,等两者都准备好了,告诉消息中间件,然后再分别提交事务。
但此时存在问题,如果A系统事务提交成功了,但是B系统在提交的时候网络波动或者各种原因提交失败了,其实还是会失败的。

整个流程中,我们能保证是:
- 业务主动方本地事务提交失败,业务被动方不会收到消息的投递。
- 只要业务主动方本地事务执行成功,那么消息服务一定会投递消息给下游的业务被动方,并最终保证业务被动方一定能成功消费该消息(消费成功或失败,即最终一定会有一个最终态)。
不过呢技术就是这样,各种极端的情况我们都需要考虑,也很难有完美的方案,所以才会有这么多的方案三段式、TCC、最大努力通知等等分布式事务方案,大家只需要知道为啥要做,做了有啥好处,有啥坏处,在实际开发的时候都注意下就好好了,系统都是根据业务场景设计出来的,离开业务的技术没有意义,离开技术的业务没有底气。
还是那句话:没有最完美的系统,只有最适合的系统。
sql语句
可以把 SQL 分为两个部分:数据操作语言 (DML) 和 数据定义语言 (DDL)。
对数据库
1
2
3
4
5
6
7
8
9
CREATE DATABASE test;#新建数据库
DROP DATABASE test;#删除数据库
USE test;#切换数据库
SHOW TABLES;#查看数据表
DESC students;#查看表结构
SHOW CREATE TABLE students;#查看创建表的SQL语句
DROP TABLE students;#删除表
ALTER TABLE students ADD COLUMN birth VARCHAR(10) NOT NULL;#修改表
ALTER TABLE students DROP COLUMN birthday;#删除列
对数据表
select
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
SELECT 列名称 FROM 表名称 #查询表中的某列
SELECT 列1,列2 FROM 表名称 #查询表中多列
SELECT * FROM 表名称#*查询所有列
SELECT DISTINCT 列名称 FROM 表名称#查询时去除重复值
SELECT * FROM Persons WHERE City='Beijing'#查找city为北京的所有行
SELECT * FROM Persons WHERE Year>1965#查找year大于1965的行
SELECT * FROM Persons WHERE FirstName='Thomas' AND LastName='Carter'#使用 AND 来显示所有姓为 "Carter" 并且名为 "Thomas" 的人
SELECT * FROM Persons WHERE firstname='Thomas' OR lastname='Carter'#使用 OR 来显示所有姓为 "Carter" 或者名为 "Thomas" 的人:
SELECT * FROM Persons WHERE (FirstName='Thomas' OR FirstName='William')
AND LastName='Carter'#组合使用and和or
SELECT Company, OrderNumber FROM Orders ORDER BY Company#以字母顺序显示公司名称
SELECT Company, OrderNumber FROM Orders ORDER BY Company, OrderNumber#以字母顺序显示公司名称(Company),并以数字顺序显示顺序号(OrderNumber)
SELECT Company, OrderNumber FROM Orders ORDER BY Company DESC # 以逆字母顺序显示公司名称
SELECT Company, OrderNumber FROM Orders ORDER BY Company DESC, OrderNumber ASC#以逆字母顺序显示公司名称,并以数字顺序显示顺序号
SELECT * FROM xueyuanxingbie WHERE college IN ('人文学院','信息学院')#查询指定行
SELECT * FROM Persons
WHERE LastName
BETWEEN 'Adams' AND 'Carter'# 会选取介于两个值之间的数据范围。这些值可以是数值、文本或者日期。
SELECT * FROM Persons
WHERE LastName
NOT BETWEEN 'Adams' AND 'Carter'使用 NOT 操作符显示范围之外的人
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo
FROM Persons, Orders
WHERE Persons.Id_P = Orders.Id_P #引用两个表
INSERT INTO
1
INSERT INTO table_name (列1, 列2,...) VALUES (值1, 值2,....)#我指定所要插入数据的列
UPDATE
1
UPDATE <表名> SET 字段1=值1, 字段2=值2, ... WHERE ...; #Update 语句用于修改表中的数据
DELETE 语句
1
2
DELETE FROM 表名称 WHERE 列名称 = 值 #DELETE 语句用于删除表中的行
DELETE FROM table_name#删除所有行
Truncate
truncate的作用是清空表或者说是截断表,只能作用于表。truncate的语法很简单,后面直接跟表名即可,例如: truncate table tbl_name 或者 truncate tbl_name 。
truncate与drop,delete的对比
上面说过truncate与delete,drop很相似,其实这三者还是与很大的不同的,下面简单对比下三者的异同。
truncate与drop是DDL语句,执行后无法回滚;delete是DML语句,可回滚。 truncate只能作用于表;delete,drop可作用于表、视图等。 truncate会清空表中的所有行,但表结构及其约束、索引等保持不变;drop会删除表的结构及其所依赖的约束、索引等。 truncate会重置表的自增值;delete不会。 truncate不会激活与表有关的删除触发器;delete可以。 truncate后会使表和索引所占用的空间会恢复到初始大小;delete操作不会减少表或索引所占用的空间,drop语句将表所占用的空间全释放掉。
通过前面介绍,我们很容易得出truncate语句的使用场景,即该表数据完全不需要时可以用truncate。如果想删除部分数据用delete,注意带上where子句;如果想删除表,当然用drop;如果想保留表而将所有数据删除且和事务无关,用truncate即可;如果和事务有关,或者想触发trigger,还是用delete;如果是整理表内部的碎片,可以用truncate然后再重新插入数据。
#####
LIKE
1
2
3
4
5
6
7
8
SELECT * FROM Persons
WHERE City LIKE 'N%'#"Persons" 表中选取居住在以 "N" 开始的城市里的人
SELECT * FROM Persons
WHERE City LIKE '%g'#从 "Persons" 表中选取居住在以 "g" 结尾的城市里的人
SELECT * FROM Persons
WHERE City LIKE '%lon%'#从 "Persons" 表中选取居住在包含 "lon" 的城市里的人
SELECT * FROM Persons
WHERE City NOT LIKE '%lon%'从 "Persons" 表中选取居住在不包含 "lon" 的城市里的人
sql左连接 ,右连接,内连接和全外连接
- left join :返回包括左表中的所有记录和右表中连接字段相等的记录。
- right join :返回包括右表中的所有记录和左表中连接字段相等的记录。
- inner join :只返回两个表中连接字段相等的行。(交集)
- full join:返回左右表中所有的记录和左右表中连接字段相等的记录。
SQL中char、varchar、nvarchar的区别?
char存储定长数据很方便,索引效率高。
如:char(8),你输入的字符小于8时,它会再后面补空值。当你输入的字符大于指定的数时,它会截取超出的字符。
varchar存储不定长数据,存储效率低。长度为 n 个字节的可变长度且非 Unicode 的字符数据。VARCHAR类型的实际长度是它的值的实际长度+1,这一个字节用于保存实际使用了多大的长度。
如:我们只知道它不可能超过10个字符,把它定义为 VARCHAR(10)是最合算的
nvarchar(n)包含 n 个字符的可变长度 Unicode 字符数据。汉字两个字节,英文一个字节,避免混乱。
一般来说,如果含有中文字符,用nchar/nvarchar,如果纯英文和数字,用char/varchar。
从空间上考虑,用varchar合适;从效率上考虑,用char合适,关键是根据实际情况找到权衡点。
SQL注入是什么,如何避免SQL注入?
SQL 注入就是在用户输入的字符串中加入 SQL 语句,如果在设计不良的程序中忽略了检查,那么这些注入进去的 SQL 语句就会被数据库服务器误认为是正常的 SQL 语句而运行,攻击者就可以执行计划外的命令或访问未被授权的数据。
SQL注入的原理
- 恶意拼接查询
- 利用注释执行非法命令。
- 传入非法参数
- 添加额外条件
避免SQL注入
- 过滤输入内容,校验字符串
- 参数化查询
- 安全测试、安全审计
- 开发过程中避免sql注入
- 避免使用动态SQL:避免将用户的输入数据直接放入 SQL 语句中,最好使用准备好的语句和参数化查询,这样更安全。
- 不要将敏感数据保留在纯文本中:加密存储在数据库中的私有/机密数据,这样可以提供了另一级保护,以防攻击者成功地排出敏感数据。
- 限制数据库权限和特权:将数据库用户的功能设置为最低要求;这将限制攻击者在设法获取访问权限时可以执行的操作。
- 避免直接向用户显示数据库错误:攻击者可以使用这些错误消息来获取有关数据库的信息。
MySql-sql语句性能分析
使用EXPLAIN关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的。分析你的查询语句或是表结构的性能瓶颈
消息队列
消息队列(MQ),是一种应用程序对应用程序的通信方法。应用程序通过写和检索出入列队的针对应用程序的数据(消息)来通信,而无需专用连接来链接它们。
消息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信,直接调用通常是用于诸如远程过程调用的技术。排队指的是应用程序通过队列来通信。队列的使用除去了接收和发送应用程序同时执行的要求。
mq的本质
对于 MQ 来说,其实不管是 RocketMQ、Kafka 还是其他消息队列,它们的本质都是:一发一存一消费。再直白点就是一个「转发器」。
生产者先将消息投递一个叫做「队列」的容器中,然后再从这个容器中取出消息,最后再转发给消费者,仅此而已。

上面这个图便是消息队列最原始的模型,它包含了两个关键词:消息和队列。
1、消息:就是要传输的数据,可以是最简单的文本字符串,也可以是自定义的复杂格式(只要能按预定格式解析出来即可)。 2、队列:大家应该再熟悉不过了,是一种先进先出数据结构。它是存放消息的容器,消息从队尾入队,从队头出队,入队即发消息的过程,出队即收消息的过程。
原始模型的进化
再看今天我们最常用的消息队列产品(RocketMQ、Kafka 等等),你会发现:它们都在最原始的消息模型上做了扩展,同时提出了一些新名词,比如:主题(topic)、分区(partition)、队列(queue)等等。
要彻底理解这些五花八门的新概念,我们化繁为简,先从消息模型的演进说起(道理好比:架构从来不是设计出来的,而是演进而来的)
队列模型
最初的消息队列就是上一节讲的原始模型,它是一个严格意义上的队列(Queue)。消息按照什么顺序写进去,就按照什么顺序读出来。不过,队列没有 “读” 这个操作,读就是出队,从队头中 “删除” 这个消息。

生产者–>队列(队尾->队头)–>消费者
这便是队列模型:它允许多个生产者往同一个队列发送消息。但是,如果有多个消费者,实际上是竞争的关系,也就是一条消息只能被其中一个消费者接收到,读完即被删除。
发布-订阅模型
如果需要将一份消息数据分发给多个消费者,并且每个消费者都要求收到全量的消息。很显然,队列模型无法满足这个需求。
一个可行的方案是:为每个消费者创建一个单独的队列,让生产者发送多份。这种做法比较笨,而且同一份数据会被复制多份,也很浪费空间。
为了解决这个问题,就演化出了另外一种消息模型:发布-订阅模型。

在发布-订阅模型中,存放消息的容器变成了 “主题”,订阅者在接收消息之前需要先 “订阅主题”。最终,每个订阅者都可以收到同一个主题的全量消息。
仔细对比下它和 “队列模式” 的异同:生产者就是发布者,队列就是主题,消费者就是订阅者,无本质区别。唯一的不同点在于:一份消息数据是否可以被多次消费。
小结
最后做个小结,上面两种模型说白了就是:单播和广播的区别。而且,当发布-订阅模型中只有 1 个订阅者时,它和队列模型就一样了,因此在功能上是完全兼容队列模型的。
这也解释了为什么现代主流的 RocketMQ、Kafka 都是直接基于发布-订阅模型实现的?此外,RabbitMQ 中之所以有一个 Exchange 模块?其实也是为了解决消息的投递问题,可以变相实现发布-订阅模型。
包括大家接触到的 “消费组”、“集群消费”、“广播消费” 这些概念,都和上面这两种模型相关,以及在应用层面大家最常见的情形:组间广播、组内单播,也属于此范畴。
透过模型看 MQ 的应用场景
目前,MQ 的应用场景非常多,大家能倒背如流的是:系统解耦、异步通信和流量削峰。除此之外,还有延迟通知、最终一致性保证、顺序消息、流式处理等等。
那到底是先有消息模型,还是先有应用场景呢?答案肯定是:先有应用场景(也就是先有问题),再有消息模型,因为消息模型只是解决方案的抽象而已。
MQ 经过 30 多年的发展,能从最原始的队列模型发展到今天百花齐放的各种消息中间件(平台级的解决方案),我觉得万变不离其宗,还是得益于:消息模型的适配性很广。
我们试着重新理解下消息队列的模型。它其实解决的是:生产者和消费者的通信问题。那它对比 RPC 有什么联系和区别呢?

通过对比,能很明显地看出两点差异:
1、引入 MQ 后,由之前的一次 RPC 变成了现在的两次 RPC,而且生产者只跟队列耦合,它根本无需知道消费者的存在。 2、多了一个中间节点「队列」进行消息转储,相当于将同步变成了异步。
再返过来思考 MQ 的所有应用场景,就不难理解 MQ 为什么适用了?因为这些应用场景无外乎都利用了上面两个特性。
举一个实际例子,比如说电商业务中最常见的「订单支付」场景:在订单支付成功后,需要更新订单状态、更新用户积分、通知商家有新订单、更新推荐系统中的用户画像等等。

引入 MQ 后,订单支付现在只需要关注它最重要的流程:更新订单状态即可。其他不重要的事情全部交给 MQ 来通知。这便是 MQ 解决的最核心的问题:系统解耦。
改造前订单系统依赖 3 个外部系统,改造后仅仅依赖 MQ,而且后续业务再扩展(比如:营销系统打算针对支付用户奖励优惠券),也不涉及订单系统的修改,从而保证了核心流程的稳定性,降低了维护成本。
这个改造还带来了另外一个好处:因为 MQ 的引入,更新用户积分、通知商家、更新用户画像这些步骤全部变成了异步执行,能减少订单支付的整体耗时,提升订单系统的吞吐量。这便是 MQ 的另一个典型应用场景:异步通信。
除此以外,由于队列能转储消息,对于超出系统承载能力的场景,可以用 MQ 作为 “漏斗” 进行限流保护,即所谓的流量削峰。
我们还可以利用队列本身的顺序性,来满足消息必须按顺序投递的场景;利用队列 + 定时任务来实现消息的延时消费 ……
MQ 其他的应用场景基本类似,都能回归到消息模型的特性上,找到它适用的原因,这里就不一一分析了。
总之,就是建议大家多从复杂多变的实践场景再回归到理论层面进行思考和抽象,这样能吃得更透。
如何设计一个mq?
任何 MQ 无外乎:一发一存一消费,这是 MQ 最核心的功能需求。另外,从技术维度来看 MQ 的通信模型,可以理解成:两次 RPC + 消息转储。
1、直接利用成熟的 RPC 框架(Dubbo 或者 Thrift),实现两个接口:发消息和读消息。 2、消息放在本地内存中即可,数据结构可以用 JDK 自带的 ArrayBlockingQueue 。
如何设计一个 MQ?
1、需要从功能性需求(收发消息)和非功能性需求(高性能、高可用、高扩展等)两方面入手。
2、功能性需求不是重点,能覆盖 MQ 最基础的功能即可,至于延时消息、事务消息、重试队列等高级特性只是锦上添花的东西。
3、最核心的是:能结合功能性需求,理清楚整体的数据流,然后顺着这个思路去考虑非功能性的诉求如何满足,这才是技术难点所在。
https://www.zhihu.com/question/54152397
kafka消费数据是怎么消费的,用的是什么方式?
Kafka消费数据的方式主要包含如下几种:
1、指定多主题消费
1
consumer.subscribe(Arrays.asList(“t4”,“t5”));
2、指定分区消费
1
consumer.assign(list);
3、手动修改偏移量
1
2
3
4
5
consumer.commitSync(); //提交当前消费偏移量
consumer.commitSync(Map<TopicPartition, OffsetAndMetadata>) //提交指定偏移量
consumer.assign(Arrays.asList(tp));
4、seek,修改偏移量搜索指针,顺序读取数据
1
2
3
consumer.assign(Arrays.asList(tp));
consumer.seek(tp,0);
操作系统
进程和线程的区别
进程:一个在内存中运行的应用程序。每个进程都有自己独立的一块内存空间,一个进程可以有多个线程,比如在Windows系统中,一个运行的xx.exe就是一个进程。
线程:进程中的一个执行任务(控制单元),负责当前进程中程序的执行。一个进程至少有一个线程,一个进程可以运行多个线程,多个线程可共享数据。
根本区别:进程是操作系统资源分配的基本单位,而线程是任务调度和执行的基本单位。
线程与进程的关系
(1)一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程;
(2)资源分配给进程,同一进程内的所有线程共享该进程的所有资源;
(3)线程在执行过程中需要协作同步。不同进程中的线程之间要利用消息通信的方法实现同步;
(4)处理机分配给线程,即真正在处理机上运行的是线程;
(5)线程是进程的一个执行单元,也是进程内的可调用实体。
协程
协程,英文Coroutines,是一种基于线程之上,但又比线程更加轻量级的存在,这种由程序员自己写程序来管理的轻量级线程叫做『用户空间线程』,具有对内核来说不可见的特性。
是自主开辟的异步任务。正如一个进程可以拥有多个线程一样,一个线程也可以拥有多个协程。而协程的目的就是当出现长时间的I/O操作时,通过让出目前的协程调度,执行下一个任务的方式,来消除ContextSwitch上的开销。
协程特点
线程的切换由操作系统负责调度,协程由用户自己进行调度,因此减少了上下文切换,提高了效率。
线程的默认Stack大小是1M,而协程更轻量,接近1K。因此可以在相同的内存中开启更多的协程。
由于在同一个线程上,因此可以避免竞争关系而使用锁。
适用于被阻塞的,且需要大量并发的场景。但不适用于大量计算的多线程,遇到此种情况,更好实用线程去解决。
协程和线程的比较
| 比较项 | 线程 | 协程 |
|---|---|---|
| 占用资源 | 初始单位为1MB,固定不可变 | 初始一般为 2KB,可随需要而增大 |
| 调度所属 | 由 OS 的内核完成 | 由用户完成 |
| 切换开销 | 涉及模式切换(从用户态切换到内核态)、16个寄存器、PC、SP…等寄存器的刷新等 | 只有三个寄存器的值修改 - PC / SP / DX. |
| 性能问题 | 资源占用太高,频繁创建销毁会带来严重的性能问题 | 资源占用小,不会带来严重的性能问题 |
| 数据同步 | 需要用锁等机制确保数据的一直性和可见性 | 不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。 |
进程间通信的常见方式,线程间通信的常用方式,通信速度
进程:
- 管道:管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。速度慢,容量有限
- 信号:信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
- 信号量 : 信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。不能传递复杂消息,只能用来同步
- 消息队列:消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。容量受到系统限制,且要注意第一次读的时候,要考虑上一次没有读完数据的问题。
- 共享内存:共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号两,配合使用,来实现进程间的同步和通信。能够很容易控制容量,速度快,但要保持同步,比如一个进程在写的时候,另一个进程要注意读写的问题,相当于线程中的线程安全,当然,共享内存区同样可以用作线程间通讯,不过没这个必要,线程间本来就已经共享了一块内存的。
线程:全局变量,Message消息机制,CEvent对象
单工、半双工及全双工之间的区别
1、单工数据传输只支持数据在一个方向上传输;在同一时间只有一方能接受或发送信息,不能实现双向通信,举例:电视,广播。
2、半双工数据传输允许数据在两个方向上传输,但是,在某一时刻,只允许数据在一个方向上传输,它实际上是一种切换方向的单工通信;在同一时间只可以有一方接受或发送信息,可以实现双向通信。举例:对讲机。
3.全双工数据通信允许数据同时在两个方向上传输,因此,全双工通信是两个单工通信方式的结合,它要求发送设备和接收设备都有独立的接收和发送能力;在同一时间可以同时接受和发送信息,实现双向通信,举例:电话通信。

多进程和多线程区别
多进程:操作系统中同时运行的多个程序
多线程:在同一个进程中同时运行的多个任务
并发性和并行性
并发意味着多个任务,这些任务在重叠的时间段内开始,运行并完成,没有特定的顺序。并行性是指多个任务或独特任务的多个部分同时运行时(例如,在多核处理器上)。
并发与并行之间的区别
并发性是指两个任务可以在重叠的时间段内启动,运行并完成。并行是指任务在同一时间运行,例如在多核处理器上。
并发性是独立执行的进程的组成,而并行则是同时执行(可能相关)的计算。
并发是一次处理很多事情。并行是一次做很多事情。
一个应用程序可以是并发的 - 但不是并行的,这意味着它可以同时处理多个任务,但是没有两个任务在同一时刻即时执行。
应用程序可以是并行的,但不是并发的,这意味着它可以同时处理多核CPU中任务的多个子任务。
应用程序既不是并行也不是并发的,这意味着它可以按顺序逐个处理所有任务。
应用程序既可以并行也可以并发,这意味着它可以同时在多核CPU中同时处理多个任务。
什么是互斥锁、读写锁?
相交进程之间的关系主要有两种,同步与互斥。
互斥:是指某一资源同时只允许一个访问者对其进行访问,具有唯一性和排它性。但互斥无法限制访问者对资源的访问顺序,即访问是无序的。
同步:是指在互斥的基础上(大多数情况),通过其它机制实现访问者对资源的有序访问。在大多数情况下,同步已经实现了互斥,特别是所有写入资源的情况必定是互斥的。少数情况是指可以允许多个访问者同时访问资源。
读写锁特点:
- 多个读者可以同时进行读
- 写者必须互斥(只允许一个写者写,也不能读者写者同时进行)
- 写者优先于读者(一旦有写者,则后续读者必须等待,唤醒时优先考虑写者)
互斥锁特点:
- 一次只能一个线程拥有互斥锁,其他线程只有等待
什么是线程安全,如何保证?
- 线程安全: 线程安全就是多线程访问时,采用了加锁机制,当一个线程访问该类的某个数据时,进行保护,其他线程不能进行访问直到该线程读取完,其他线程才可使用。不会出现数据不一致或者数据污染。 线程不安全就是不提供数据访问保护,有可能出现多个线程先后更改数据造成所得到的数据是脏数据。
- 如何保证呢: 1、使用线程安全的类; 2、使用synchronized同步代码块,或者用Lock锁; > 由于线程安全问题,使用synchronized同步代码块 原理:当两个并发线程访问同一个对象object中的这个synchronized(this)同步代码块时,一个时间内只能有一个线程得到执行。 另一个线程必须等待当前线程执行完这个代码块以后才能执行该代码块。 3、多线程并发情况下,线程共享的变量改为方法局部级变量;
同步异步
区别
同步:所有的操作都做完,才返回给用户。即写完数据库之后,再响应用户,用户体验不好。用户在线等待的时间长,给用户一种卡死了的感觉(就是系统迁移中,点击了迁移,界面就不动了,但是程序还在执行,卡死了的感觉)。这种情况下,用户不能关闭界面,如果关闭了,即迁移程序就中断了。
异步:不用等所有操作都做完,就相应用户请求。即先响应用户请求,然后慢慢去写数据库,用户体验较好。为了避免短时间大量的数据库操作,就使用缓存机制,也就是消息队列。将用户请求放入消息队列,并反馈给用户,系统迁移程序已经启动,你可以关闭浏览器了。然后程序再慢慢地去写入数据库去。这就是异步。但是用户没有卡死的感觉,会告诉你,你的请求系统已经响应了。你可以关闭界面了。
引入消息队列机制,虽然可以保证用户请求的快速响应,但是并没有使得我数据迁移的时间变短(即80万条数据写入mysql需要1个小时,用了redis之后,还是需要1个小时,只是保证用户的请求的快速响应。用户输入完http url请求之后,就可以把浏览器关闭了,干别的去了。如果不用redis,浏览器不能关闭)。
同步异步的优缺点?
1、同步的执行效率会比较低,耗费时间,但有利于我们对流程进行控制,避免很多不可掌控的意外情况; 2、异步的执行效率高,节省时间,但是会占用更多的资源,也不利于我们对进程进行控制
异步使用的场景:
1、不涉及共享资源,或对共享资源只读,即非互斥操作 2、没有时序上的严格关系 3、不需要原子操作,或可以通过其他方式控制原子性 4、常用于IO操作等耗时操作,因为比较影响客户体验和使用性能 5、不影响主线程逻辑
用户注册,购买商品,发验证码,消息通知,优惠券发放,订单流程处理,
同步的使用场景:
不使用异步的时候
同步就没有任何价值了吗?
银行的转账功能。
使用异步后的烦恼
烦恼一: 数据丢失的风险
解决方式:先写日志或数据库,后放入异步队列.
烦恼二:对其他系统的压力变大
解决方式:使用一定的限流和熔断,对其他系统进行保护。
烦恼三:数据保存后异步任务未执行
解决方式:使用异步任务补偿的方式,定期从数据库中获取数据,放到队列中进行执行,执行后更新数据状态位。
烦恼四:怎样队列长设置和消费者数量
解决方式:使用实际的压力测试来获得队列长度。或者使用排队论的数学公式得到初步的值,然后进行实际压测。
最后介绍一下项目中的经验:
-
量力而行:根据业务特点进行技术选型,业务量小尽量避免使用异步。有所为,有所不为
数据说话:异步时一定要进行必要的压力测试
先找出系统的关键点:优化单体系统内的性能,再通过整体系统分解来全局优化
根据团队和项目的特点选择框架。
内核态和用户态的划分与切换
虚拟地址怎么映射到物理地址
简述 IO 多路复用
一句话解释:单线程或单进程同时监测若干个文件描述符是否可以执行IO操作的能力。
I/O模型
阻塞IO
这是最常用的简单的IO模型。阻塞IO意味着当我们发起一次IO操作后一直等待成功或失败之后才返回,在这期间程序不能做其它的事情。阻塞IO操作只能对单个文件描述符进行操作,详见read或write。
非阻塞IO
我们在发起IO时,通过对文件描述符设置O_NONBLOCK flag来指定该文件描述符的IO操作为非阻塞。非阻塞IO通常发生在一个for循环当中,因为每次进行IO操作时要么IO操作成功,要么当IO操作会阻塞时返回错误EWOULDBLOCK/EAGAIN,然后再根据需要进行下一次的for循环操作,这种类似轮询的方式会浪费很多不必要的CPU资源,是一种糟糕的设计。和阻塞IO一样,非阻塞IO也是通过调用read或writewrite来进行操作的,也只能对单个描述符进行操作。
IO多路复用
IO多路复用在Linux下包括了三种,select、poll、epoll,抽象来看,他们功能是类似的,但具体细节各有不同:首先都会对一组文件描述符进行相关事件的注册,然后阻塞等待某些事件的发生或等待超时。更多细节详见下面的 “具体怎么用”。IO多路复用都可以关注多个文件描述符,但对于这三种机制而言,不同数量级文件描述符对性能的影响是不同的,下面会详细介绍。
信号驱动IO
信号驱动IO是利用信号机制,让内核告知应用程序文件描述符的相关事件。这里有一个信号驱动IO相关的例子。
但信号驱动IO在网络编程的时候通常很少用到,因为在网络环境中,和socket相关的读写事件太多了,比如下面的事件都会导致SIGIO信号的产生:
- TCP连接建立
- 一方断开TCP连接请求
- 断开TCP连接请求完成
- TCP连接半关闭
- 数据到达TCP socket
- 数据已经发送出去(如:写buffer有空余空间)
上面所有的这些都会产生SIGIO信号,但我们没办法在SIGIO对应的信号处理函数中区分上述不同的事件,SIGIO只应该在IO事件单一情况下使用,比如说用来监听端口的socket,因为只有客户端发起新连接的时候才会产生SIGIO信号。
异步IO
异步IO和信号驱动IO差不多,但它比信号驱动IO可以多做一步:相比信号驱动IO需要在程序中完成数据从用户态到内核态(或反方向)的拷贝,异步IO可以把拷贝这一步也帮我们完成之后才通知应用程序。我们使用 aio_read 来读,aio_write 写。
同步IO vs 异步IO 1. 同步IO指的是程序会一直阻塞到IO操作如read、write完成 2. 异步IO指的是IO操作不会阻塞当前程序的继续执行 所以根据这个定义,上面阻塞IO当然算是同步的IO,非阻塞IO也是同步IO,因为当文件操作符可用时我们还是需要阻塞的读或写,同理IO多路复用和信号驱动IO也是同步IO,只有异步IO是完全完成了数据的拷贝之后才通知程序进行处理,没有阻塞的数据读写过程。
如何保障消息100%投递成功、消息幂等性?
幂等含义
在分布式应用中,幂等是非常重要的,也就是相同条件下对一个业务的操作,不管操作多少次,结果都是一样。
为什么要有幂等这种场景?
为什么要有幂等这种场景?因为在大的系统中,都是分布式部署,如:订单业务 和 库存业务有可能都是独立部署的,都是单独的服务。用户下订单,会调用到订单服务和库存服务。
因为分布式部署,很有可能在调用库存服务时,因为网络等原因,订单服务调用失败,但其实库存服务已经处理完成,只是返回给订单服务处理结果时出现了异常。这个时候一般系统会作补偿方案,也就是订单服务再次放起库存服务的调用,库存减1。
这样就出现了问题,其实上一次调用已经减了1,只是订单服务没有收到处理结果。现在又调用一次,又要减1,这样就不符合业务了,多扣了。
幂等这个概念就是,不管库存服务在相同条件下调用几次,处理结果都一样。这样才能保证补偿方案的可行性。
计算机组成原理
计算机的基本组成
冯·诺依曼计算机的特点机器以运算器为中心)
- 计算机由控制器(分析和执行机器指令并控制各部件的协同工作)、运算器(根据控制信号对数据进行算术运算和逻辑运算)、存储器(内存存储中间结果,外存存储需要长期保存的信息)、输入设备(接收外界信息)和输出设备(向外界输送信息)五大部件组成
- 指令(程序)和数据以二进制不加区别地存储在存储器中
- 程序自动运行
现代计算机由三大部分组成(已经转化为以存储器为中心)
- CPU(Central Processing Unit) 中央处理器,核心部件为ALU(Arithmetic Logic Unit,算术逻辑单元)和CU(Control Unit,控制单元)
- I/O设备(受CU控制)
- 主存储器(Main Memory,MM),分为RAM(随机存储器)和ROM(只读存储器) //CPU与MM合成主机,I/O设备可称为外部设备
计算机网络类
ip端口
源ip-寄信人的地址
目的ip-收信人的地址
端口-收/寄件人姓名
端口号-具体的服务
长连接与短连接的区别以及使用场景
短连接
连接->传输数据->关闭连接
比如HTTP是无状态的的短链接,浏览器和服务器每进行一次HTTP操作,就建立一次连接,但任务结束就中断连接。因为连接后接收了数据就断开了,所以每次数据接受处理不会有联系。 这也是HTTP协议无状态的原因之一。
长连接
连接->传输数据->保持连接 -> 传输数据-> ………..->直到一方关闭连接,多是客户端关闭连接。
长连接指建立SOCKET连接后不管是否使用都保持连接,但安全性较差。
什么时候用长连接,短连接?
长连接多用于操作频繁,点对点的通讯,而且连接数不能太多情况,。每个TCP连接都需要三步握手,这需要时间,如果每个操作都是先连接,再操作的话那么处理速度会降低很多,所以每个操作完后都不断开,次处理时直接发送数据包就OK了,不用建立TCP连接。例如:数据库的连接用长连接, 如果用短连接频繁的通信会造成socket错误,而且频繁的socket 创建也是对资源的浪费。
而像WEB网站的http服务一般都用短链接,因为长连接对于服务端来说会耗费一定的资源,而像WEB网站这么频繁的成千上万甚至上亿客户端的连接用短连接会更省一些资源,如果用长连接,而且同时有成千上万的用户,如果每个用户都占用一个连接的话,那可想而知吧。所以并发量大,但每个用户无需频繁操作情况下需用短连好。
什么是协议?网络有哪些协议?
发送端和接收端双方协商约定的规则就是协议。它能保证数据正确发送到指定端。
五层模型
应用层:DHCP、HTTP、HTTPS、RTMP、DNS、RPC。。
传输层:UDP、TCP
网络层:ICMP、IP、OSPF。。。
链路层:ARP、VLAN,WiFi,以太网
物理层:网络跳线
计算机网络七层模型
OSI中的上面4层(应用层、表示层、会话层、传输层)为高层,定义了程序的功能;下面3层(网络层、数据链路层、物理层)为低层,主要是处理面向网络的端到端数据流。

一个设备工作在哪一层,关键看它工作时利用哪一层的数据头部信息。网桥工作时,是以MAC头部来决定转发端口的,因此显然它是数据链路层的设备。 具体说: 物理层:网卡,网线,集线器,中继器,调制解调器 数据链路层:网桥,交换机 网络层:路由器 网关工作在第四层传输层及其以上。 集线器是物理层设备,采用广播的形式来传输信息。 交换机就是用来进行报文交换的机器。多为链路层设备(二层交换机),能够进行地址学习,采用存储转发的形式来交换报文.。 路由器的一个作用是连通不同的网络,另一个作用是选择信息传送的线路。选择通畅快捷的近路,能大大提高通信速度,减轻网络系统通信负荷,节约网络系统资源,提高网络系统畅通率。
物理层
数据以比特流的形式在物理层传输
设备有中继器、集线器(作用:转发、放大信号)
数据链路层
负责将数据组帧,实现链路管理、流量控制和差错控制
协议有GBN后退N帧协议、SR选择重传协议、以太网协议
设备有网桥、交换机(作用:根据MAC地址对帧进行过滤转发,可以隔绝冲突域,不能隔绝广播域)
冲突域:同一时间内只能有一台设备发送信息的范围
广播域:网络中能接收到任意设备发出的广播帧的设备的集合
网络层
提供主机和主机之间的逻辑通信
协议有ARP协议、OSPF/RIP路由寻址协议、DHCP协议、ICMP协议、IGMP组播协议、IP协议、CIDR协议
设备有路由器(作用:转发分组)
传输层
提供端到端的可靠报文传递,负责将数据传送至对应端口,提供进程和进程之间的逻辑通信
协议有TCP UDP协议
会话层
负责建立、管理、终止进程之间的会话
表示层
对上层数据或者信息进行变换,以保证一个主机应用层信息可以被另一个主机应用层所理解,包括数据加密、格式转换、压缩等
应用层
为操作系统或者网络应用程序提供访问网络的接口 协议有HTTP FTP SMTP DNS协议
HTTP
超文本传输协议(HTTP, HyperText Transfer Protocol)是一种无状态的协议,它位于OSI七层模型的应用层。HTTP客户端会根据需要构建合适的HTTP请求方法,而HTTP服务器会根据不同的HTTP请求方法做出不同的响应。
HTTPS的介绍
HTTPS是一种应用层协议,本质上来说它是HTTP协议的一种变种。HTTPS比HTTP协议安全,因为HTTP是明文传输,而HTTPS是加密传输,加密过程中使用了三种加密手段,分别是证书,对称加密和非对称加密。HTTPS相比于HTTP多了一层SSL/TSL,其构造如下:

HTTP请求格式
第一部分:请求行
在请求行中,URL就是要访问的网站地址,版本为1.1,方法就是
GET、POST之类的。第二部分:请求头部
首部字段都是key: value的形式,如
Content-Type: application/json; charset=UTF-8。Content-Type是指正文的格式。如
Cache-Control: no-store, no-cache, must-revalidate。Cache-Control是用来控制缓存的,当客户端发送的请求中包含max-age指令时,如果判定缓存层中,资源的缓存时间数值比指定时间的数值小,那么客户端可以接受缓存的资源;当指定max-age值为0,那么缓存层通常需要将请求转发给应用集群。第三部分:请求正文
就是数据信息,塞的数据。
HTTP响应报文格式
第一部分:状态行
由3部分组成,分别为:协议版本,状态码,状态码描述,之间由空格分隔
第二部分:响应头部
Key-value形式的数据,和请求头部类似
第三部分:响应正文
和请求类似
HTTP 请求方法
HTTP1.0 定义了三种请求方法: GET, POST 和 HEAD方法。
HTTP1.1 新增了六种请求方法:OPTIONS、PUT、PATCH、DELETE、TRACE 和 CONNECT 方法。
GET:获取数据。产生一个TCP数据包,浏览器会把http header和data一并发送出去,服务器响应200
POST:修改数据。产生两个TCP数据包,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok
HEAD:HEAD方法与GET方法一样,都是向服务器发出指定资源的请求。但是,服务器在响应HEAD请求时不会回传资源的内容部分,即:响应主体。这样,我们可以不传输全部内容的情况下,就可以获取服务器的响应头信息。HEAD方法常被用于客户端查看服务器的性能。
put:增
delete:删
http状态码
1xx 表示正在处理
- 100 continue 一切正常 可以继续发送(据说是http报文中如果有post方法的话 会先把请求行发送过去,然后返回100,然后再发送请求头部和请求体给服务器端)
2xx 成功 表示请求已经正常处理
- 200 OK 一切正常返回数据
- 204 No content 请求正常处理,但是没有数据返回
- 206 指定范围返回(http1.1以上支持的断点续传功能相关)
3xx 重定向 浏览器需要一些额外的操作才能完成请求
- 301 永久性重定向
- 302 暂时性重定向(跟http劫持有关,运营商可以通过DNS劫持和http劫持两种,返回一个302,然后让用户跳转到处理好的携带广告的页面)
- 303 暂时性重定向 但是服务器端明确说明希望浏览器用get方法来请求资源
- 304 浏览器附带了请求的条件,服务器端允许访问,但是不满足请求条件
4xx 客户端错误
- 400 客户端的请求有语法错误
- 403 forbidden 客户端申请访问的资源被禁止访问
- 404 Not found 客户端申请访问的资源不存在
- 405 Method not allowed 客户端请求方法被禁止
5xx 服务器端错误
- 500 服务器在请求处理时内部出错
- 501 服务器不具备完成请求的功能,如无法识别请求方法
- 502 服务器作为网关或代理,从上游服务器获得无效响应
- 503 Bad Gateway 服务器处于停机维护/超负荷状态
- 504 Gateway timeout服务器作为网关或代理,没有及时从上游服务器获得响应
https加密原理
使用两把密钥的公开密钥加密
公开密钥加密使用一对非对称的密钥。一把叫做私钥,另一把叫做公钥。私钥不能让其他任何人知道,而公钥则可以随意发布,任何人都可以获得。使用公钥加密方式,发送密文的一方使用对方的公钥进行加密处理,对方收到被加密的信息后,再使用自己的私钥进行解密。利用这种方式,不需要发送用来解密的私钥,也不必担心密钥被攻击者窃听而盗走。
过程 ①服务器把自己的公钥登录至数字证书认证机构。 ②数字证书机构把自己的私有密钥向服务器的公开密码部署数字签名并颁发公钥证书。 ③客户端拿到服务器的公钥证书后,使用数字证书认证机构的公开密钥,向数字证书认证机构验证公钥证书上的数字签名。以确认服务器公钥的真实性。 ④使用服务器的公开密钥对报文加密后发送。 ⑤服务器用私有密钥对报文解密。
https://blog.csdn.net/qq_32998153/article/details/80022489
HTTPS和HTTP的区别
(1)HTTPS是密文传输,HTTP是明文传输;
(2)默认连接的端口号是不同的,HTTPS是443端口,而HTTP是80端口;
(3)HTTPS请求的过程需要CA证书要验证身份以保证客户端请求到服务器端之后,传回的响应是来自于服务器端,而HTTP则不需要CA证书;
(4)HTTPS=HTTP+加密+认证+完整性保护。
Get和post的区别
注意存放在请求行和请求体的不是方法 而是请求/提交的数据 post和get方法都是在请求行中啦
最直观的区别就是GET把参数包含在URL中,POST通过request body传递参数。
- GET使用URL或Cookie传参。而POST将数据放在BODY中。
- GET的URL会有长度上的限制,则POST的数据则可以非常大。
- get只接受acsii字符,post没有限制,get只支持url编码,post没有限制
- POST比GET安全,因为数据在地址栏上不可见。
- get不能改变服务器的数据,一般用于从服务器获取数据,是幂等的;post可以改变服务器的数据,不是幂等的。
- 一般get请求用来获取数据,post请求用来发送数据。
- get请求参数会被完整地保存在浏览器历史记录中,post请求参数则不会保留
- get请求可以被浏览器主动缓存,下一次若传输数据相同,则优先返回缓存中的内容,以加快显示速度。post请求不会,除非手动设置一下
rpc协议(thrift)和http协议有什么区别
本质区别:就是RPC主要工作在TCP协议之上,而HTTP服务主要是工作在HTTP协议之上,效率rpc更高。接口可能返回一个JSON字符串或者是XML文档。然后客户端再去处理这个返回的信息,从而可以比较快速地进行开发。
HTTP接口:相比RPC,HTTP接口对于在接口不多、系统与系统交互较少的情况下,解决信息孤岛初期常使用的一种通信手段;优点就是简单、直接、开发方便。利用现成的http协议进行传输。适合小企业。
thrift:对于大型企业来说,内部子系统较多、接口非常多的情况下,RPC框架的好处就显示出来了。
- Thrift是一个跨语言的服务开发框架。它有一个代码生成器来对它所定义的IDL定义文件自动生成服务代码框架。用户只要在其之前进行二次开发就行,对于底层的RPC通讯等都是透明的。
- 自定义协议,减少数据传输,通过rpc协议我们可以精简请求的数据,来尽可能少的传输我们的数据。当然,rpc也可以通过http协议来进行传输。
- 使用长连接:直接基于socket进行连接,不用每个请求都重新走三次握手的流程,减少了网络开销。
- Thrift默认提供了数据与实体类的转换,不需要我们显示的进行数据与实体类的转换。
- thrift性能好。
- RPC框架一般都有注册中心,有丰富的监控管理;发布、下线接口、动态扩展等,对调用方来说是无感知、统一化的操作
coocike和session?
- cookie数据存放在客户的浏览器上,session数据放在服务器上。
- session是针对每一个用户的,变量的值保存在服务器上,用一个sessionID来区分是哪个用户session变量。
- 保存这个session id的方式可以采用cookie。
- cookie不是很安全,别人可以分析存放在本地的cookie并进行cookie欺骗,考虑到安全应当使用session。
- session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能,考虑到减轻服务器性能方面,应当使用cookie。
- 单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
-
所以个人建议:将登陆信息等重要信息存放为session,其他信息如果需要保留,可以放在cookie中
长链接和短链接
短连接
连接->传输数据->关闭连接 比如HTTP是无状态的的短链接,浏览器和服务器每进行一次HTTP操作,就建立一次连接,但任务结束就中断连接。因为连接后接收了数据就断开了,所以每次数据接受处理不会有联系。 这也是HTTP协议无状态的原因之一。
长链接
连接->传输数据->保持连接 -> 传输数据-> ………..->直到一方关闭连接,多是客户端关闭连接。长连接指建立SOCKET连接后不管是否使用都保持连接,但安全性较差。
长连接多用于操作频繁,点对点的通讯,而且连接数不能太多情况,。每个TCP连接都需要三步握手,这需要时间,如果每个操作都是先连接,再操作的话那么处理速度会降低很多,所以每个操作完后都不断开,次处理时直接发送数据包就OK了,不用建立TCP连接。例如:数据库的连接用长连接, 如果用短连接频繁的通信会造成socket错误,而且频繁的socket 创建也是对资源的浪费。
而像WEB网站的http服务一般都用短链接,因为长连接对于服务端来说会耗费一定的资源,而像WEB网站这么频繁的成千上万甚至上亿客户端的连接用短连接会更省一些资源,如果用长连接,而且同时有成千上万的用户,如果每个用户都占用一个连接的话,那可想而知吧。所以并发量大,但每个用户无需频繁操作情况下需用短连好。
tcp三次握手和四次挥手吗?
建立一个TCP连接时,需要客户端和服务器总共发送3个包。三次握手的最主要目的是「双方确认自己与对方的发送与接收是正常的」。
原理:
第一次握手:客户发送请求给服务器,并进入等待状态
第二次握手:服务器收到客户请求,确认并回复请求
第三次握手:客户端收到并向服务器发送确认,建立连接
完成三次握手,客户端与服务器开始传送数据。
通俗理解:
Client:喂!听的到吗?
Server:可以,我听的到。
Client:好的,我们都能互相听的对方的话,可以开始通信了。
TCP的连接的拆除需要发送四个包,因此称为四次挥手(four-way handshake)。客户端或服务器均可主动发起挥手动作。
原理:
第一次挥手:Client发送一个FIN,用来关闭CIient到Server的数据传输,Client进入FIN_WAIT_1状态。
第二次挥手:Server收到FIN后,发送一个ACK给Client,确认序号为收到,序号+1(与SYN相同,一个FIN占用一个序号),Server进入CLOSE_WAIT状态。
第三次挥手:Server发送一个FIN,用来关闭Server到Client的数据传输,Server进入LAST_ACK状态。
第四次挥手:Client收到FIN后,Client进入TIME_WAIT状态,接着发送一个ACK给Server,确认序号为收到,序号+1,Server进入CLOSED状态,完成四次挥手。
通俗理解:
Client:我已经说完了。
Server:我收到了,等等我,我还没说完。
Server:好了,我也说完了。
Client:好的,那我们通信结束。
三次握手为什么不用两次,或者四次?
因为只有三次才最合适,三次通信是最小值,两次通信无法确认双方收发功能的正常,而四次通信则显得有些冗余。
为什么建立连接是三次握手,而关闭连接却是四次挥手?
这是因为服务端在LISTEN状态下,收到建立连接请求的SYN报文后,把ACK和SYN放在一个报文里发送给客户端。而关闭连接是,当收到对方的FIN报文是,仅仅表示对方不再发送数据了,但是还能接收数据,已方也未必全部数据都发送给对方了,所以已方可以立即close,也可以发送一些数据给对方后,再发送FIN报文给对方来表示同意现在关闭连接,因此,已方ACK和FIN一般都会分开发送。
tcp和udp的区别
tcp连接就像打电话,两者之间必须有一条不间断的通路,数据不到达对方,对方就一直在等待,除非对方直接挂电话。先说的话先到,后说的话后到,有顺序。
udp就象寄一封信,发信者只管发,不管到。但是你的信封上必须写明对方的地址。发信者和收信者之间没有通路,靠邮电局联系。信发到时可能已经过了很久,也可能根本没有发到。先发的信未必先到,后发的也未必后到。
1、TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接 2、TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保 证可靠交付。 3、TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等) 4、每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信 5、TCP首部开销20字节;UDP的首部开销小,只有8个字节 6、TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道
输入URL到显示网页发生了什么
https://www.zhihu.com/question/34873227/answer/518086565
- DNS 解析:将域名解析成 IP 地址
- DNS解析过程,浏览器缓存—>操作系统缓存—>本地DNS—>根据转发模式选择迭代还是递归查询
- TCP 连接:TCP 三次握手
- 浏览器向服务器发送 HTTP 请求报文
- 传输层上建立TCP连接,网络层用到了IP协议(负责在网络层传输数据),还会用到RIP或者OSPF进行路由选择,然后用ARP协议解析IP地址对应的MAC地址,使得数据能够在数据链路层上进行传输(不应该是最后到物理层传输吗)。
- 服务器请求处理并返回一个HTTP响应报文
- HTTP响应报文的结构,状态码
- 服务器返回一个HTML响应,浏览器收到HTML响应并渲染界面
- 根据 HTML 解析出 DOM 树
- 根据 CSS 解析生成 CSS 规则树
- 结合 DOM 树和 CSS 规则树,生成渲染树
- 根据渲染树计算每一个节点的信息
- 根据计算好的信息绘制页面
- 断开连接:TCP 四次挥手
IPv4与IPv6的区别是什么?
1.IPv6的地址空间更大。IPv4中规定IP地址长度为32,即有2^32-1个地址;而IPv6中IP地址的长度为128,即有2^128-1个地址。夸张点说就是,如果IPV6被广泛应用以后,全世界的每一粒沙子都会有相对应的一个IP地址。 2.IPv6的路由表更小。IPv6的地址分配一开始就遵循聚类(Aggregation)的原则,这使得路由器能在路由表中用一条记录(Entry)表示一片子网,大大减小了路由器中路由表的长度,提高了路由器转发数据包的速度。 3.IPv6的组播支持以及对流的支持增强。这使得网络上的多媒体应用有了长足发展的机会,为服务质量控制提供了良好的网络平台。 4.IPv6加入了对自动配置的支持。这是对DHCP协议的改进和扩展,使得网络(尤其是局域网)的管理更加方便和快捷。 5.IPv6具有更高的安全性。在使用IPv6网络中,用户可以对网络层的数据进行加密并对IP报文进行校验,这极大地增强了网络安全
TCP/IP的网络分层模型,传输层的协议有哪些?
为什么TCP/UDP是传输层协议?
TCP 如何保障数据包有效
(1)为了保证数据包的可靠传递,发送方必须把已发送的数据包保留在缓冲区; (2)并为每个已发送的数据包启动一个超时定时器; (3)如在定时器超时之前收到了对方发来的应答信息(可能是对本包的应答,也可以是对本包后续包的应答),则释放该数据包占用的缓冲区; (4)否则,重传该数据包,直到收到应答或重传次数超过规定的最大次数为止。 (5)接收方收到数据包后,先进行CRC校验,如果正确则把数据交给上层协议,然后给发送方发送一个累计应答包,表明该数据已收到,如果接收方正好也有数据要发给发送方,应答包也可方在数据包中捎带过去。
Http和Socket的区别
http 为短连接:客户端发送请求都需要服务器端回送响应.请求结束后,主动释放链接,因此为短连接。通常的做法是,不需要任何数据,也要保持每隔一段时间向服务器发送”保持连接”的请求。这样可以保证客户端在服务器端是”上线”状态。
HTTP连接使用的是”请求-响应”方式,不仅在请求时建立连接,而且客户端向服务器端请求后,服务器才返回数据。
Socket为长连接:通常情况下Socket 连接就是 TCP 连接,因此 Socket 连接一旦建立,通讯双方开始互发数据内容,直到双方断开连接。在实际应用中,由于网络节点过多,在传输过程中,会被节点断开连接,因此要通过轮询高速网络,该节点处于活跃状态。
*Socket 原理*
Socket 连接,至少需要一对套接字,分为 clientSocket,serverSocket 连接分为3个步骤:
(1) 服务器监听:服务器并不定位具体客户端的套接字,而是时刻处于监听状态;
(2) 客户端请求:客户端的套接字要描述它要连接的服务器的套接字,提供地址和端口号,然后向服务器套接字提出连接请求;
(3) 连接确认:当服务器套接字收到客户端套接字发来的请求后,就响应客户端套接字的请求,并建立一个新的线程,把服务器端的套接字的描述发给客户端。一旦客户端确认了此描述,就正式建立连接。而服务器套接字继续处于监听状态,继续接收其他客户端套接字的连接请求.
什么是死锁?如何发生?如何测试?
什么是SQL注入?如何避免?写出你了解的其他常见安全问题。
什么是 DDoS 攻击?
可能我举个例子会更加形象点。
我开了一家有五十个座位的重庆火锅店,由于用料上等,童叟无欺。平时门庭若市,生意特别红火,而对面二狗家的火锅店却无人问津。二狗为了对付我,想了一个办法,叫了五十个人来我的火锅店坐着却不点菜,让别的客人无法吃饭。
上面这个例子讲的就是典型的 DDoS 攻击,全称是 Distributed Denial of Service,翻译成中文就是分布式拒绝服务。一般来说是指攻击者利用“肉鸡”对目标网站在较短的时间内发起大量请求,大规模消耗目标网站的主机资源,让它无法正常服务。在线游戏、互联网金融等领域是 DDoS 攻击的高发行业。
如何应对 DDoS 攻击?
高防服务器
还是拿我开的重庆火锅店举例,高防服务器就是我给重庆火锅店增加了两名保安,这两名保安可以让保护店铺不受流氓骚扰,并且还会定期在店铺周围巡逻防止流氓骚扰。
高防服务器主要是指能独立硬防御 50Gbps 以上的服务器,能够帮助网站拒绝服务攻击,定期扫描网络主节点等,这东西是不错,就是贵
黑名单
面对火锅店里面的流氓,我一怒之下将他们拍照入档,并禁止他们踏入店铺,但是有的时候遇到长得像的人也会禁止他进入店铺。这个就是设置黑名单,此方法秉承的就是“错杀一千,也不放一百”的原则,会封锁正常流量,影响到正常业务。
DDoS 清洗
DDos 清洗,就是我发现客人进店几分钟以后,但是一直不点餐,我就把他踢出店里。
DDoS 清洗会对用户请求数据进行实时监控,及时发现DOS攻击等异常流量,在不影响正常业务开展的情况下清洗掉这些异常流量。
CDN 加速,我们可以这么理解:为了减少流氓骚扰,我干脆将火锅店开到了线上,承接外卖服务,这样流氓找不到店在哪里,也耍不来流氓了。
在现实中,CDN 服务将网站访问流量分配到了各个节点中,这样一方面隐藏网站的真实 IP,另一方面即使遭遇 DDoS 攻击,也可以将流量分散到各个节点中,防止源站崩溃。
Nginx是什么
Nginx (engine x) 是一个高性能的HTTP和反向代理web服务器,同时也提供了IMAP/POP3/SMTP服务
Nginx是一款轻量级的Web 服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器,在BSD-like 协议下发行。其特点是占有内存少,并发能力强
热部署,不需要重新启动
如何热部署
nginx -s reload
这个命令会重新加载配置,而不中断正在运行的连接。它会启动一个新的工作进程,将新配置加载到这个新进程中,然后将请求逐渐切换到新的工作进程。一旦所有请求都切换到新进程,旧的进程会被关闭。
Nginx的反向代理
正向代理:(翻墙-浏览器中配置代理服务器)我们直接用国内的服务器无法访问国外的服务器,或者是访问很慢。所以我们需要在本地搭建一个服务器来帮助我们去访问。那这种就是正向代理。
反向代理: 比如:我们访问淘宝的时候,淘宝内部肯定不是只有一台服务器,它的内部有很多台服务器,那我们进行访问的时候,因为服务器中间session不共享,那我们是不是在服务器之间访问需要频繁登录,那这个时候淘宝搭建一个过渡服务器,对我们是没有任何影响的,我们是登录一次,但是访问所有,这种情况就是 反向代理。对我们来说,客户端对代理是无感知的,客户端不需要任何配置就可以访问,我们只需要把请求发送给反向代理服务器,由反向代理服务器去选择目标服务器获取数据后,再返回给客户端,此时反向代理服务器和目标服务器对外就是一个服务器,暴露的是代理服务器地址,隐藏了真实服务器的地址。(在服务器中配置代理服务器)
负载均衡
简单来说就是:现有的请求使服务器压力太大无法承受,所有我们需要搭建一个服务器集群,去分担原先一个服务器所承受的压力,那现在我们有ABCD等等多台服务器,我们需要把请求分给这些服务器,但是服务器可能大小也有自己的不同,所以怎么分?如何分配更好?又是一个问题。
Nginx给出来三种关于负载均衡的方式:
轮询法(默认方法):
每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。
适合服务器配置相当,无状态且短平快的服务使用。也适用于图片服务器集群和纯静态页面服务器集群。
weight权重模式(加权轮询):
指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况。
这种方式比较灵活,当后端服务器性能存在差异的时候,通过配置权重,可以让服务器的性能得到充分发挥,有效利用资源。weight和
访问比率成正比,用于后端服务器性能不均的情况。权重越高,在被访问的概率越大、
ip_hash:
上述方式存在一个问题就是说,在负载均衡系统中,假如用户在某台服务器上登录了,那么该用户第二次请求的时候,因为我们是负载均衡系统,每次请求都会重新定位到服务器集群中的某一个,那么已经登录某一个服务器的用户再重新定位到另一个服务器,其登录信息将会丢失,这样显然是不妥的。 我们可以采用ip_hash指令解决这个问题,如果客户已经访问了某个服务器,当用户再次访问时,会将该请求通过哈希算法,自动定位到该服务器。每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题。
linux
linux基础知识
统计一个文件中的某个单词个数以及替换
| grep -o ‘root’ a.txt | wc - |
替换sed
查看进程、top命令、查看磁盘
ps-aux df-h
TOP命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况。
查看CPU状态
vmstat
查看负载
1
2
3
4
5
6
uptime
08:21:34 up 36 min, 2 users, load average: 0.00, 0.00, 0.00
#当前服务器时间: 08:21:34
#当前服务器运行时长 36 min
#当前用户数 2 users
#当前的负载均衡 load average 0.00, 0.00, 0.00,分别取1min,5min,15min的均值
系统平均负载是指在特定时间间隔内运行队列中的平均进程数。
如果每个CPU内核的当前活动进程数不大于3的话,那么系统的性能是良好的。如果每个CPU内核的任务数大于5,那么这台机器的性能有严重问题。如果你的linux主机是1个双核CPU的话,当Load Average 为6的时候说明机器已经被充分使用了。
其他查看当前用户和系统负载
top命令是动态查看进程变化,监控linux的系统状况;它是常用的性能分析工具,能够实时显示系统资源各个进程占用状况,类是windows的任务管理器。
| -h | -v: 显示帮助或者版本信息】 |
-c: 命令行列显示程序名以及参数
-d: 启动时设置刷新时间间隔
-H: 设置线程模式
-i: 只显示活跃进程
-n: 显示指定数量的进程
-p: 显示指定PID的进程
-u: 显示指定用户的进程
文件文档管理命令
pwd 查看当前目录路径
sudo -i 进入root用户
ssh dp@
cd(Change Directory)命令
cd..返回上一级
ls(list)命令
ls查看当前目录
ls-l输出详细信息(权限文件名等)
ls-lh输出方便人看的详细信息(GB MB)
ls-a显示所有文件(包括隐藏文件)
ls-l查看文件的权限
chmod 修改权限命令
chmod +x test.sh 给脚本赋予可执行的权限
touch命令
touch file1 file2 file3 建立多个文件
mkdir(make directory)新建文件夹
mkdir folder2新建文件夹
mkdir folder2/f2在folder2里再建个f2
rm 移除文件
rm file1移除单个文件
rm -i有提示的删除(避免误删)
rm -r 2.6.0 删除2.6.0文件夹(整个文件夹)
rm * -rf删除文件夹下面所有文件
rm xxx* 删除某些固定字母开头的文件
rm *.txt删除一类文件
| find . -name “*.c” | xargs rm -rf 发现当前文件夹及其子目录下面都没有了.c文件。 |
mv 移动命令
例:mv /home/1.txt /opt/”,这个命令是将/home目录下的1.txt移动到 /opt目录下,命令执行后home目录下的1.txt将会被删除。
cp (copy) 复制命令
cp file1 file1copy 把1复制出copy
cp -i老文件 新文件(检查覆盖)
cp file1 folder1/复制文件到文件夹
cp -R folder1/ folder2/ 复制文件夹,-R
mv剪切命令
mv file1 folder1/ 移动去另一个文件夹
$ mv file1 file1rename
tar解压缩
$ tar zxvf 文件 f后面一定跟着压缩文件的名称,
nano(文字编辑or写代码)
nano t.py新建python脚本 ctrl+X保存退出
python t.py执行
cat(catenate)命令
查看日志
cd /data/datapipeline/log/sinkdp/ 先进入到日志的目录
| cat 423ef181118c.log | grep Insert 查看423ef181118c日志,查找Insert字符串 |
| cat 423ef181118c* | grep Insert 查所有的日志 从中查找Insert字符串 |
创建目的地/任务失败: dp-thrall-webservice
tailf /data/datapipeline/log/dpthrall/thrall.log
源端报错:sourcedp
ls -lrht /data/datapipeline/log/sourcedp
(注:上述命令结果最后面的即是最新日志)
目的端报错:sinkdp
写入目的地失败ls -lrht /data/datapipeline/log/sinkdp
(注:上述命令结果最后面的即是最新日志)
容器日志查看方式(以zookeeper为例):
docker logs -f docker ps -a | grep zookeeper| awk '{print $1}'
find和grep
grep命令是一种强大的文本搜索工具,grep搜索内容串可以是正则表达式,允许对文本文件进行模式查找。如果找到匹配模式,grep打印包含模式的所有行。
find通常用来再特定的目录下搜索符合条件的文件,也可以用来搜索特定用户属主的文件。
grep
从单个文件中查找指定的字符串grep “this” demo_file
从多个文件中查找指定的字符串grep “this” demo_*
查询且忽略大小写grep -i
搜索所有的文件及子目录grep -r
显示行数grep -n
| 查找多个关键字 grep aaa log/public.log | grep bbb |
wget 下载链接
查看端口
1
netstat -tunlp | grep 6379
netstat -a
telnet命令(测试端口连通)
ping 10.163.243.210
telnet 10.163.243.210 8098
ssh
测试端口是否连通
用法: ssh -v -p port username@ip
-v 调试模式(会打印日志).
-p 指定端口
软连接ln
建立一个软连接
ln -s file1 file1soft
删除软连接
rm -fr xxxx/ 加了个/ 这个是删除文件夹
rm -fr xxxx 没有/ 这个是删除软链接
关于corn表达式
corn表达式 0 48 14 ? * 1 意思是每周一的14:48
系统磁盘管理命令
df命令
df -h 以容易阅读的方式显示磁盘分区使用情况
df /etc/dhcp显示指定文件所在分区的磁盘使用情况
fdisk磁盘分区
fdisk -l查看所有分区情况
查看cpu
cat /proc/cpuinfo
linux文件权限说明(drwxr-xr-x)

面试题:
线上服务可能因为种种原因导致挂掉怎么办?
linux下的后台进程管理利器 supervisor
每次文件修改后再linux执行 service supervisord restart
linux下批量替换文件中的字段
比如我这里要将qt目录下 所有文件中的aaa替换成bbb
1
2
3
4
5
6
7
8
9
sed -i "s/aaa/bbb/g" `grep aaa -rl ./qt`
格式: sed -i "s/查找字段/替换字段/g" `grep 查找字段 -rl 路径`
其中
-i 表示inplace edit,就地修改文件
-r 表示搜索子目录
-l 表示输出匹配的文件名
硬链接和软链接
Linux 链接分两种,一种被称为硬链接(Hard Link),另一种被称为符号链接(Symbolic Link)。默认情况下,ln 命令产生硬链接。
区别:
- 文件系统层次:
- 硬链接: 在文件系统层次上创建的链接,多个硬链接共享相同的 inode 和数据块。
- 软链接: 也在文件系统层次上创建的链接,但它实际上是一个包含目标文件路径的特殊文件。
- Inode 和数据:
- 硬链接: 所有硬链接指向相同的 inode 和数据块,共享相同的文件内容。
- 软链接: 软链接有自己的 inode 和数据块,其数据块包含指向另一文件的路径。
- 目录中的多个条目:
- 硬链接: 一个文件可以有多个硬链接,它们可以存在于同一目录或不同目录中。
- 软链接: 一个文件只有一个软链接,它占据目录中的一个条目。
- 删除原文件的影响:
- 硬链接: 删除一个硬链接不会影响其他硬链接,只有当所有硬链接都被删除时,文件的数据才会被释放。
- 软链接: 删除原始文件不会影响软链接。
- 权限和所有权:
- 硬链接: 硬链接和原始文件之间没有所谓的“主”链接,它们都是相等的,没有区别。
- 软链接: 软链接可能引发权限问题。如果原始文件的权限被更改或文件被删除,软链接可能会失效。
联系:
- 链接的目的:
- 硬链接和软链接都用于创建文件之间的链接,允许一个文件被多个路径引用。
- 文件内容的共享:
- 硬链接和原始文件共享相同的 inode 和数据块,因此它们实际上指向相同的文件内容。
- 软链接引用另一文件的路径,因此它们不共享文件内容。
- 操作和使用:
- 硬链接通常更高效,但不能跨文件系统使用。
- 软链接更灵活,可以跨文件系统,但相对于硬链接来说可能会稍慢。
总体而言,硬链接和软链接提供了不同的文件链接机制,每种都有其适用的场景。硬链接通常用于在同一文件系统内共享文件内容,而软链接则更灵活,可以用于跨文件系统的链接。