校招之语言基础+数据结构
语言基础基础
解释型和编译型语言的区别
编译型语言:
在程序执行前,需要把源代码编译成机器语言的文件,再执行时可以直接使用该编译结果,以后不需要再次编译。
优点:运行效率高
缺点:难以移植
解释型语言:
代码执行时才一行行动态翻译执行
优点:无需翻译器,方便程序移植;可以交互式运行
缺点:运行效率较低
java
C/C++基础
vector
vector 常被称为向量容器,因为该容器擅长在尾部插入或删除元素,在常量时间内就可以完成,时间复杂度为O(1);而对于在容器头部或者中部插入或删除元素,则花费时间要长一些(移动元素需要耗费时间),时间复杂度为线性阶O(n)。
可以简单的认为,向量是一个能够存放任意类型的动态数组。
list
list是由双向链表实现的,因此内存空间是不连续的。只能通过指针访问数据,所以list的随机存取非常没有效率,时间复杂度为o(n);但由于链表的特点,能高效地进行插入和删除。
总之,如果需要高效的随机存取,而不在乎插入和删除的效率,使用vector;如果需要大量的插入和删除,而不关心随机存取,则应使用list。
gcc 和 gdb简介
Unix上使用的c语言编译器gcc,在Linux上的派生就是gcc。在使用vi或gedit编写完源程序之后,返回到shell界面,使用gcc对源程序进行编泽的命令为:
Linux包含了一个叫gdb的GNU调试程序。gdb是一个用来调试c和c++程序的强力调试器。它使用户能在程序运行时观察程序的内部结构和内存的使用情况。以下是gdb所提供的一些功能:
char data[0](柔性数组)
**用途 :**长度为0的数组的主要用途是为了满足需要变长度的结构体。
用法 **:**在一个结构体的最后 ,申明一个长度为0的数组,就可以使得这个结构体是可变长的。对于编译器来说,此时长度为0的数组并不占用空间,因为数组名本身不占空间,它只是一个偏移量, 数组名这个符号本身代 表了一个不可修改的地址常量(注意:数组名永远都不会是指针!),但对于这个数组的大小,我们可以进行动态分配。
请仔细理解后半部分,对于编译器而言,数组名仅仅是一个符号,它不会占用任何空间,它在结构体中,只是代表了一个偏移量,代表一个不可修改的地址常量!
对于0长数组的这个特点,很容易构造出变长结构体,如缓冲区,数据包等等:
这样的变长数组常用于网络通信中构造不定长数据包,不会浪费空间浪费网络流量,比如我要发送1024字节的数据,如果用定长包,假设定长包的长度为2048,就会浪费1024个字节的空间,也会造成不必要的流量浪费
Map
map是STL的一个关联容器,它提供一对一的hash。
map的功能
自动建立key - value的对应。key 和 value可以是任意你需要的类型,包括自定义类型。
使用map
技术侧面试题: c++基础: (1)struct和union的区别(2)函数指针的声明(3)explicit关键字 (4)局部变量和全局变量在内存分配上的区别(5)深拷贝和浅拷贝的区别 (6)构造函数能不能是虚函数?析构函数能不能是虚函数?什么是纯虚函数?(7)内存泄漏的概念,有什么方法能避免内存泄漏 代码能力:(1)strcdy SucDy (2)链表的实现(声明、插入删除)(3)快速排序(4)TopN算法 简单算法: (1)快速排序有chara[nlcharb[m]两个数组n>m>1000b数组中的元素a中都有现在需要生成数组c将a中有b中没有的元素都放到c里面,要求高效,用c/c++语言实现。 (2)海量日志数据,提取出某日访问百度次数最多的那个IP。(hash分桶统计)
python基础
- 变量:是一个系统表的元素,拥有指向对象的连接空间
- 对象:被分配的一块内存,存储其所代表的值
- 引用:是自动形成的从变量到对象的指针,每个对象都会在内存中申请开辟一块新的空间来保存对象;对象在内存中所在位置的地址称之为引用。
- 类型:属于对象,而非变量
python2和python3的区别?
-
print函数
-
print 'Hello world!' print ('Hello world!') # 注意print后面有个空格 print('Hello world!') # print()不能带有任何其它参数 -
但在Python3中只能使用后两者,print语句被Python3废弃,只能使用print函数
-
-
Unicode
- Python2中是ASCII编码,需要更改字符集才能正常支持中文,所以在.py文件中会看到# -- coding: utf-8 --
- Python3中字符串是Unicode (utf-8)编码,支持中文做标识符
-
除法运算
- 在Python2中/除法规则是整数相除的结果是一个整数,把小数部分完全忽略掉,浮点数除法会保留小数点的部分得到一个浮点数的结果。
- 在Python3中/除法不再这么做了,对于整数之间的相除,结果也会是浮点数。
- 不过对于//除法,这种除法叫做floor除法,会对除法的结果自动进行一个floor操作,在Python2和Python3中是一致的。
-
异常处理
- Python2时代,所有类型的对象都是可以被直接抛出的,在Python3时代,只有继承自BaseException的对象才可以被抛出。
- 异常StandardError 被Python3废弃,统一使用Exception
-
xrange和range
- Python3中不再使用xrange方法,只有range方法
- range在Python2中返回列表,而在Python3中返回range可迭代对象
-
不等运算符
- Python2中不等于有两种写法 != 和 <>
- Python3中去掉了<>, 只有!=一种写法
-
去掉了repr表达式“
- Python2中反引号
相当于repr函数的作用 Python3中去掉了这种写法,只允许使用repr函数
- Python2中反引号
-
数据类型
- 在Python2中long是比int取值范围更大的整数,Python3中取消了long类型,int的取值范围扩大到之前的long类型范围
- 新增了bytes类型,对应于Python2版本的八位串,定义一个bytes字面量的方法如下b=b’china’
- str 对象和 bytes 对象可以使用 .encode() (str -> bytes) 或 .decode() (bytes -> str)方法相互转化
- dict的.keys()、.items 和.values()方法返回迭代器,只能通过循环取值,不能通过索引取值,而之前的iterkeys()等函数都被废弃。同时去掉的还有 dict.has_key(),可以用 in来代替
Python元组和列表的区别?
元组和列表最大的区别就是,列表中的元素可以进行任意修改,就好比是用铅笔在纸上写的字,写错了还可以擦除重写;而元组中的元素无法修改,除非将元组整体替换掉,就好比是用圆珠笔写的字,写了就擦不掉了,除非换一张纸。
可以理解为,tuple 元组是一个只读版本的 list 列表。
字典如何查询?列表如何查询?字典和列表的区别?字典的key可以是什么?可以是list吗?为什么?
python可变数据类型和不可变数据类型
- 可变数据类型:当该数据类型对应的变量的值发生了变化时,如果它对应的内存地址不发生改变,通俗点说就是原地改变,那么这个数据类型就是可变数据类型。list(列表)、dict(字典)、set(集合,不常用)
- 不可变数据类型:当该数据类型对应的变量的值发生了变化时,如果它对应的内存地址发生了改变,相当于把原来的值复制一份后才能改变,那么这个数据类型就是不可变数据类型。数值类型(int、float、bool)、string(字符串)、tuple(元组)
总结:可变数据类型更改值后,内存地址不发生改变。不可变数据类型更改值后,内存地址发生改变。
赋值(复制)、浅拷贝与深拷贝
赋值: 只是复制了新对象的引用,不会开辟新的内存空间。
赋值其实就是将一个对象的地址赋值给一个变量,使得变量指向该内存地址。
浅拷贝: 创建新对象,其内容是原对象的引用。
浅拷贝之所以称为浅拷贝,只是拷贝数据的第一层,不会拷贝子对象。
浅拷贝有三种形式: 切片操作,工厂函数,copy模块中的copy函数。
如: lst = [1,2,[3,4]]
切片操作:lst1 = lst[:] 或者 lst1 = [each for each in lst]
工厂函数:lst1 = list(lst)
copy函数:lst1 = copy.copy(lst)
-
不可变类型的浅拷贝
如果只是针对不可变的数据类型(字符串、数值型、布尔值)和“赋值”的情况一样,浅拷贝的对象和原数据对象是相同的内存地址,(id()函数用于获取对象的内存地址)
-
可变类型的浅拷贝 (列表、字典、集合)
- 不存在嵌套类型的可变类型数据:复制的对象中无复杂子对象,原来值的改变并不会影响浅复制的值,同时浅复制的值改变也并不会影响原来的值。原来值的id值与浅复制原来的值不同。
- 存在嵌套类型的可变类型数据:复制的对象中有复杂子对象(例如列表中的一个子元素是一个列表),如果不改变其中复杂子对象,浅复制的值改变并不会影响原来的值。 但是改变原来的值中的复杂子对象的值会影响浅复制的值。浅拷贝只复制最外层的数据,导致内存地址发生变化,里面数据的内存地址不会变。
深拷贝:和浅拷贝对应,深拷贝拷贝了对象的所有元素,包括多层嵌套的元素。深拷贝出来的对象是一个全新的对象,不再与原来的对象有任何关联。
- 不可变类型的深拷贝:针对不可变数据类型的深浅拷贝,其结果是相同的,地址值和拷贝后的值都是一样的。
- 可变类型的深拷贝
- 不存在嵌套类型的可变类型数据:
- 深拷贝对最外层数据是只拷贝数据,会开辟新的内存地址来存放数据。
- 深拷贝对里面的不可变数据类型直接复制数据和地址,和可变类型的浅拷贝是相同的效果。
- 存在嵌套类型的可变类型数据:
- 列表整体:对整个存在嵌套类型的数据进行深浅拷贝都会发生内存的变化,因为数据本身是可变的。
- 列表中的普通元素:元素属于数值型,是不可变类型。三者的地址是相同的。
- 列表中的列表:嵌套了一个列表,深拷贝是不同的,因为我们查看嵌套列表中的元素的内存地址,这个嵌套的列表是可变数据类型,深拷贝在拷贝了最外层之后还会继续拷贝子层级的可变类型。
- 列表中的列表中的元素:元我们查看嵌套列表中的元素的内存地址,发现它们是相同的,因为元素是数值型,是不可变的,不受拷贝的影响。
- 不存在嵌套类型的可变类型数据:
元组的深浅拷贝
元组本身是不可变数据类型,但是其中的值是可以改变的,内部可以有嵌套可变数据类型,比如列表等,会对它的拷贝结果造成影响。
不存在嵌套结构
- 当元组中不存在嵌套结构的时候,元组的深浅拷贝是相同的效果,地址都相等
存在嵌套结构
- 当元组的数据中存在嵌套的可变类型,比如列表等,深拷贝会重新开辟地址,将元组重新成成一份。
总结
- 在不可变数据类型中,深浅拷贝都不会开辟新的内存空间,用的都是同一个内存地址。
- 在存在嵌套可变类型的数据时,深浅拷贝都会开辟新的一块内存空间;同时,不可变类型的值还是指向原来的值的地址。
- **不同的是:**在嵌套可变类型中,浅拷贝只会拷贝最外层的数据,而深拷贝会拷贝所有层级的可变类型数据。
python的list和numpy.array(数组)的区别
1.list可以存放不同类型的数据,比如int,str,bool,float,list,set等,但是numpy数组中存放的数据类型必须全部相同,必须全为int或全为float
2.list中每个元素的大小可以相同,也可以不同,因此不支持一次性读取一列,而numpy数组中每个元素大小相同,支持一次性读取一列。numpy对二维数组的操作更为便捷
3.list中数据类型保存的是数据存放的地址,即指针而非数据,比如一个有四个数据的列表a=[1,2,3,4]需要4个指针和4个数据,增加了存储空间,消耗CPU,但是a=np.array([1,2,3,4])只需要存放4个数据,节省内存,方便读取和计算
4.一个numpy的array是内存中的一个连续块,array中的元素都是同一类型的,所以一旦确定了一个array,它的内存就确定了,每个元素的内存大小都确定了。而list的每个元素是一个地址的引用,这个地址又指向了另一个元素,这些元素在内存里不一定是连续的,因此每当加入新元素,其实只是把这个元素的地址添加到list中
Python中is和==的区别?
在讲is和==这两种运算符区别之前,首先要知道Python中对象包含的三个基本要素,分别是:id(身份标识)、type(数据类型)和value(值)。
is 是进行id的比较,== 是进行value的比较。
lambda函数
匿名函数形式 f=lambda x : x表达式
调用时可采用f(x)的形式 或者直接使用(可以用于return语句)
优点:没有名字,无需担心函数冲突
缺点:只能有一个表达式,没有return,返回值就是该表达式的结果
Python为什么的编码注释# -- coding:utf-8 --?
因为一般默认的是ASCII码,如果要在文件里面写中文,运行时会出现乱码,加上这句之后会把文件编码强制转换为utf-8运行时会就不会出现乱码了。
函数或变量的作用域
正常的函数/变量是public的,可以被直接引用,如x123 PI 等
xxx__变量/函数是特殊变量,虽可以被直接引用,但是有特殊的用途,比如说__init new 等
_xxx 表示半私有的变量,只能在类或者子类内使用
__xxx表示私有的变量,只能在类内使用
这两种私有变量都是应当私有 而不是一定不能访问的
类中self的概念
self代表实例本身,具体来说是该实例的内存地址
self的三种应用:
self为类中函数的第一个参数
在调用实例方法时,python解释器会自己把实例变量传递给函数中的self。如果类的实例方法的第一个参数不是代表实例的self,则调用实例方法时,该方法没有参数来接收自动传入的实例变量,程序会产生异常。
在类中,引用实例的属性 self.变量名
引用实例的属性目的是为实例绑定属性,写入或读取实例的属性
在类中,调用实例的方法 self.方法名()
python的几种变量,按照作用域划分
1.全局变量 在模块内、在所有函数之外、在class外
2.局部变量 在函数内、在class的方法内(但未加self修饰)
3.静态变量/类属性 在class内,但是不在class的方法内的。
类的所有实例均可以访问到该类属性,用类名.变量名()的方式
4.实例变量/实例属性 在class的方法内,用self修饰的变量
//实例属性的优先级高于类属性,所以若是同名,实例属性会覆盖类属性,有限输出实例属性
python的面向对象特性
1.封装 2.继承 3.多态
面向对象和面向过程语言的区别
面向对象是把问题抽象成一个个对象,给这些对象绑上属性和方法,即以功能而非步骤划分问题。优点:更易低耦合、易维护、易复用;缺点:因为需要实例化所以开销较大,性能比面向过程要低
面向过程是把问题拆分成一个个函数和数据,按照一定的顺序来执行这些方法。优点:性能较高;缺点:不易维护,不易复用
init和new的区别
相同点:两者都是类中的private函数
不同点:
__new__是在实例创建之前被调用的,任务是创建实例然后返回该实例对象,是个静态方法,至少要有一个参数cls(代表当前类),必须有返回值(即该实例对象) __init__是在实例创建完成后被调用的,设置对象属性的一些初始值,通常用在初始化一个类实例的时候,是一个实例方法,至少有一个参数self(代表当前的实例),无需返回值 即__init__在__new__之后被调用,__new__的返回值(实例)传递给__init__的第一个参数,然后由__init__设置一些实例的参数。
此外,继承自object的类才有__new__,如果定义子类的时候没有定义__new__,则会追溯到父类的__new__方法来构造该类实例,如果父类也未定义,则一直可以向上追溯到object的__new__方法
常用的模块
1.os 与操作系统交互 2.sys 3.random 生成伪随机数 4.time 可以读取时间戳或程序暂停 5.collections 提供常见的数据结构如双向队列deque、计数器Counter、默认字典defaultdict
迭代器和生成器的区别
生成器
生成器是列表生成式的简化,列表生成式一次性生成整个列表,如果列表尺寸过大而我们只需要列表的前几个数据进行处理的话就会造成大量的空间浪费,所以引入生成器。
列表生成式
三种结构:
[执行语句 for 变量 in 数据集合 ] [执行语句 for 变量 in 数据集合 if 筛选条件] [执行语句1 if 筛选条件 else 执行语句2 for 变量 in 数据集合]也可以同时使用两个for 进行嵌套循环 最终生成一个list
生成器有两种形式:
①把列表生成式中的[]改为()即可构成一个生成器。不是一次性生成列表,而是不断用next()进行调用抛出下一个值,如果超出列表范围就返回StopIteration的错误。或者可以用在for循环当中,作为可迭代对象。
②在函数中通过yield关键字定义,即需要返回数据时使用yield语句。生成器在实例化时并不会立即被执行,而是等待next()的出现,程序运行完yield后会保持当前状态并停止运行,等待下一个next()调用,从yield语句处执行。
range和xrange的区别
python2中分range()和xrange() 其中range()是生成一个list,是一个列表生成式 而xrange()是一个生成器
python3中取消了xrange() 内置的range()实际就是python2里的xrange() 返回生成器
迭代器
**迭代器的定义是可以用被next()函数调用并不断返回下一个值的对象 **
1.生成器
2.可迭代对象用iter()函数构成的迭代器 list、tuple、set、str等数据类型
装饰器
装饰器可以在不改变函数代码和调用方式的情况下给函数添加新的功能。
本质上是一个嵌套函数,接收被装饰的函数(func)作为参数,并返回一个包装过的函数,以实现不影响函数的情况下添加新的功能。抽离出大量与函数主体功能无关的代码,增加一个函数的重用性。
应用场景:性能测试(统计程序运行时间)、插入日志、权限校验
如何提高python的运行效率
使用生成器;关键代码使用外部功能包(Cython,pylnlne,pypy,pyrex);针对循环的优化–尽量避免在循环中访问变量的属性
Python中的yield用法
yield简单说来就是一个生成器,这样函数它记住上次返 回时在函数体中的位置。对生成器第 二次(或n 次)调用跳转至该函 次)调用跳转至该函 数。
python的内存管理机制
- 引用计数
- 垃圾回收
- 内存池机制
9.1 垃圾回收机制 垃圾回收机制以引用计数法为主,标记-清除为辅。
1.引用计数法 因为自动回收,所以没有内存泄漏的风险。
引用计数法是指在每个对象的结构体PyObject中定义一个计数变量ob_refcnt,计算该对象被引用的次数,有以下4种情况会造成引用计数变量的增加:1.该对象被引用;2.该对象被加入某容器(列表、字典等);3.对象被创建;4.该对象被作为参数传到函数中。
对应的python计数减少的情况为:1.该引用被释放,也就是说引用该对象的变量换了引用对象;2.该对象被从容器中删除;3.用del删除该对象;4.一个对象离开它的作用域,例如func函数全部执行完毕,非全局变量的对象引用计数器-1(这个引用是指创建引用的副本吗,为什么全局变量的对象计数器不变呢?)
当计数变量减少至0时,自动释放该变量。
优点:高效,自动释放,实时性高,即一旦没有引用立即释放;
缺点:1.增加存储空间,维护引用计数消耗资源;2.无法解决循环调用(一组未被外部使用、但相互指向的对象)的情况。
2.标记-清除法 标记-清除被作为解决循环调用的情况,辅助python进行垃圾回收
过程:①首先创建对象时,python会将其加入零代链表;②遍历零代链表,如果被本链表内的对象引用,自身的被引用数-1;③清除被引用数为0的对象;④其余未被回收的“活动对象”升级为一代链表 一代同样可能会触发gc机制,从而对一代链表标记清除,将剩下的活动对象升级为二代链表。
python的GC阈值——即何时会进行标记过程
当被分配对象的计数值与被释放对象的计数值之间的差异增长,超过某个阈值时,就会触发python的收集机制
这里采用了分代的思想,存活越久的对象越不可能是垃圾。这里对零代对象的扫描次数大于对一代对象的次数。核心行为就是:垃圾回收器会频繁地处理新对象。
9.2 内存池机制 python引用了一个内存池memory pool机制,即pymalloc机制,用于对小块内存的申请和释放。
当创建大量消耗小内存的对象时,频繁调用malloc/new会导致大量的内存碎片,导致效率降低。内存池即预先在内存中申请一定数量的、大小相等的内存块留作备用,当有新的内存需求时,就先从内存池中分配内存给该需求,不够了再去申请新的内存。对象被释放后,空闲的小内存返回内存池,避免频繁的内存释放动作。
优点:能够减少内存碎片,提升效率
当申请内存小于256k的话,就会直接在内存池中申请内存空间。如果申请内存大于256k的话则会直接执行new/malloc行为来申请新的内存空间。
python传参时需要注意什么
4.1 传入参数是否可以被修改 1.如果没有将外部变量传递到函数来(参数定义种包含该外部变量),则函数内部虽然可以使用,但是不能对该变量进行修改(会报错)——未传参的变量可使用但不可修改
2.将外部变量作为实参传递到函数中来的话,
如果外部变量是不可变对象的话不可以修改该变量的原始值——相当于“传值”的方式来传递变量,可以通过改变引用指向的方式,在函数内部获取新的不可变对象,但是对函数外部没有影响(除非加了global)
python函数传入的是原变量引用的一个副本,这两个引用(副本及原引用)在内外均指向同一个内存区(具体存值的地方)。如果在函数内部改变了引用指向的话,只是副本引用指向了一个新的内存区,函数外面的引用仍然指向原内存堆区,不会改变原变量的值(不可变对象的操作、可变对象的赋值操作)。而如果在内部通过append、remove函数改变了堆区的值的话,外部的引用仍然会改变。
可变对象与不可变对象总结
可变对象:list、dict、set 可变对象是指对象的内存值可以改变
不可变对象:int、tuple、str、bool 不可变对象是指对象的内存值不可以被改变。改变变量时,其实质是变量指向新的地址,即变量引用新的对象
4.2 传入参数的顺序和类型 参数顺序:必选参数,默认参数,可变参数,命名关键字参数,关键字参数
可变参数必须在关键字参数之前
默认参数 必须指向不可变对象
可变参数 形式def func(*可变参数) 传入参数的个数可以是0个或者多个,其实是传入一个list或者tuple,函数接收的是个tuple。如果有个list或者tuple想直接传入func的话,可以直接用func(*list)实现(即把想要传入的可变参数封装成list/tuple传入)
关键字参数 形式def func(**关键字参数) 允许传入0个或多个含参数名的参数,在函数内部组装成字典。传入的时候用参数名=参数值的形式。如果传入dict的话可以直接func(**dict)
命名关键字参数 形式def func(,city,job) 限制某几种参数名的输入,传入的时候必须只有,后面的这几种参数名可以选择,传入用fun(city=xxx,job=xxx)的形式
魔术方法
new_ 创建类并返回这个类的实例 init 可理解为“构造函数”,在对象初始化的时候调用,使用传入的参数初始化该实例 del 可理解为“析构函数”,当一个对象进行垃圾回收时调用 metaclass 定义当前类的元类 class 查看对象所属的类 base 获取当前类的父类 bases 获取当前类的所有父类 str 定义当前类的实例的文本显示内容
Python 中 with用法及原理
with 语句适用于对资源进行访问的场合,确保不管使用过程中是否发生异常都会执行必要的“清理”操作,释放资源,比如文件使用后自动关闭/线程中锁的自动获取和释放等。
如下代码:
file = open("1.txt")
data = file.read()
file.close()123上面代码存在2个问题: (1)文件读取发生异常,但没有进行任何处理; (2)可能忘记关闭文件句柄;
改进
try:
f = open('xxx')
except:
print('fail to open')
exit(-1)
try:
do something
except:
do something
finally:
f.close()1234567891011虽然这段代码运行良好,但比较冗长。 而使用with的话,能够减少冗长,还能自动处理上下文环境产生的异常。如下面代码:
with open("1.txt") as file:
data = file.read()原理:(1)紧跟with后面的语句被求值后,返回对象的“–enter–()”方法被调用,这个方法的返回值将被赋值给as后面的变量; (2)当with后面的代码块全部被执行完之后,将调用前面返回对象的“–exit–()”方法。
实际上,在with后面的代码块抛出异常时,exit()方法被执行。开发库时,清理资源,关闭文件等操作,都可以放在exit()方法中。 总之,with-as表达式极大的简化了每次写finally的工作,这对代码的优雅性是有极大帮助的。 如果有多项,可以这样写:
With open('1.txt') as f1, open('2.txt') as f2:
do somethingPython多线程的原理与实现
https://blog.csdn.net/daiyu__zz/article/details/81912018
Go 实现并发 TCP 端口扫描器
这里通过互斥锁来解决数据竞争问题,使用WaitGroup来解决协程同步的问题,TCPScanner代码如下:
package main
import (
"fmt"
"log"
"net"
"sync"
"time"
)
func main() {
var wg sync.WaitGroup
var mutex sync.Mutex
ports := make([]int, 0)
for i := 80; i <= 50000; i++ {
wg.Add(1)
go func(port int) {
defer wg.Done()
conn, err := net.DialTimeout("tcp", fmt.Sprintf("127.0.0.1:%d", port), time.Second)
if err != nil {
log.Printf("Error:%v.Port:[%d]\n", err, port)
} else {
conn.Close()
log.Printf("Connection successful.Port:[%d]\n", port)
mutex.Lock()
ports = append(ports, port)
mutex.Unlock()
}
}(i)
}
wg.Wait()
fmt.Printf("Opened ports:%v", ports)
}幂等
go基础
go语言的特性
- 并发与协程
- 基于消息传递的通信方式
- 丰富实用的内置数据类型
- 函数多返回值
- defer机制
- 反射(reflect)
- 高性能HTTP Server
- 工程管理
- 编程规范
数组array和切片slice的区别
array有长度,固定不变
var a [3]int //数组声明方式
b :=[3]int{1,2,3}//字面量初始化slice长度可变,可以直接切片数组,切片后长度就是左闭右开区间,容量是左闭到末尾
var s []int //slice声明方式
s1 :=[]int{1,2,3}//字面量初始化
s2 :=make([]int,3,10)//内置函数初始化 类型 长度 容量互斥锁和读写锁(Mutex和RWMutex)
Mutex是互斥锁的意思,也叫排他锁,同一时刻一段代码只能被一个线程运行,使用只需要关注方法Lock(加锁)和Unlock(解锁)即可。 在Lock()和Unlock()之间的代码段称为资源的临界区(critical section),是线程安全的,任何一个时间点都只能有一个goroutine执行这段区间的代码。
Golang同步锁
1 原子锁 可以借助某个信号向所有的goroutine 发送消息
互斥锁,通过 mutex, 能够将一段临界区间包含起来,只运行单个goroutine执行
Go 并发(多线程)
https://blog.csdn.net/luoye4321/article/details/82433144
1.goroutine是Go并行设计的核心。goroutine说到底其实就是线程,但是它比线程更小,十几个goroutine可能体现在底层就是五六个线程,Go语言内部帮你实现了这些goroutine之间的内存共享。执行goroutine只需极少的栈内存(大概是4~5KB),当然会根据相应的数据伸缩。也正因为如此,可同时运行成千上万个并发任务。goroutine比thread更易用、更高效、更轻便。
goroutine是通过Go的runtime管理的一个线程管理器。goroutine通过go关键字实现了,其实就是一个普通的函数。
go hello(a, b, c)2.go语言的线程通信
无论是哪种编程语言,实现多线程之间的通信方式无非是共享数据和消息两种方式。
3.go语言的线程同步
1.使用互斥锁实现线程同步
互斥锁是最简单的一种锁类型,同时也比较暴力,当一个goroutine获得了锁之后,其他goroutine就只能乖乖等到这个goroutine释放该锁。go语言使用sync.Mutex实现互斥锁。
我们通过多次运行发现,输出的结果并不总是从0到9按顺序输出,说明创建的10个goroutine并不是有序的抢占线程的执行权,也就是说这种同步并不是有序的同步,我们可以让10个goroutine一个一个的同步执行,但是并不能安排执行次序。
2.读写锁实现线程同步
从结果我们可以看出,开始的时候读线程占用读锁,并且多个线程可以同时开始读操作,但是写操作只能单个进行。
3)使用条件变量实现线程同步
go语言提供了条件变量sync.Cond,sync.Cond方法如下:
Wait,Signal,Broadcast。 Wait添加一个计数,也就是添加一个阻塞的goroutine。 Signal解除一个goroutine的阻塞,计数减一。 Broadcast接触所有wait goroutine的阻塞。
go语言多线程支持全局唯一性操作,即一个只允许goruntine调用一次,重复调用无效。
go语言还支持sync.WaitGroup``实现多个线程同步的操作。
GO 的goroutine(协程)和thread(线程)
Thread 线程 在传统的web编程中,经常要用到多线程。比如 java,来一个websocket 即开启一个thread(线程)。
而thread的数目是有限的,一般的电脑可以同时开的thread数量大概几千个。而GO语言可以开启的goroutine,却可以达到几百万个,因此很显然goroutine不等于thread。
go channel
channel 是 goroutine 之间通信的一种方式,可以类比成 Unix 中的进程的通信方式管道。
- 可以利用通道在多个gotoutine之间传递数据
- 通道类型的值本身就是并发安全的
- 在声明并初始化一个通道时需要用到go语言的内建函数make,该函数需要传递两个参数,一个是通道类型的元素类型。另一个是通道的容量,该参数是可选的,所谓通道的容量,就是指通道最多可以缓存多少个元素值。根据通道容量的大小是否大于0可以将通道分为两种类型:非缓冲通道和缓冲通道,非缓冲通道的容量为0,缓冲通道的容量大于0
channel 提供了一种通信机制,通过它,一个 goroutine 可以想另一 goroutine 发送消息。channel 本身还需关联了一个类型,也就是 channel 可以发送数据的类型。例如: 发送 int 类型消息的 channel 写作 chan int 。
channel 创建
channel 使用内置的 make 函数创建,下面声明了一个 chan int 类型的 channel:
ch := make(chan int)c和 map 类似,make 创建了一个底层数据结构的引用,当赋值或参数传递时,只是拷贝了一个 channel 引用,指向相同的 channel 对象。和其他引用类型一样,channel 的空值为 nil 。使用 == 可以对类型相同的 channel 进行比较,只有指向相同对象或同为 nil 时,才返回 true channel 的读写操作
ch := make(chan int)
// write to channel
ch <- x
// read from channel
x <- ch
// another way to read
x = <- chchannel 一定要初始化后才能进行读写操作,否则会永久阻塞。
关闭 channel
golang 提供了内置的 close 函数对 channel 进行关闭操作。
ch := make(chan int)
close(ch)有关 channel 的关闭,你需要注意以下事项:
- 关闭一个未初始化(nil) 的 channel 会产生 panic
- 重复关闭同一个 channel 会产生 panic
- 向一个已关闭的 channel 中发送消息会产生 panic
- 从已关闭的 channel 读取消息不会产生 panic,且能读出 channel 中还未被读取的消息,若消息均已读出,则会读到类型的零值。从一个已关闭的 channel 中读取消息永远不会阻塞,并且会返回一个为 false 的 ok-idiom,可以用它来判断 channel 是否关闭
- 关闭 channel 会产生一个广播机制,所有向 channel 读取消息的 goroutine 都会收到消息
ch := make(chan int, 10)
ch <- 11
ch <- 12
close(ch)
for x := range ch {
fmt.Println(x)
}
x, ok := <- ch
fmt.Println(x, ok)
-----
output:
11
12
0 falsechannel 的类型
channel 分为不带缓存的 channel 和带缓存的 channel。
无缓存的 channel
从无缓存的 channel 中读取消息会阻塞,直到有 goroutine 向该 channel 中发送消息;同理,向无缓存的 channel 中发送消息也会阻塞,直到有 goroutine 从 channel 中读取消息。
通过无缓存的 channel 进行通信时,接收者收到数据 happens before 发送者 goroutine 唤醒
有缓存的 channel
有缓存的 channel 的声明方式为指定 make 函数的第二个参数,该参数为 channel 缓存的容量
ch := make(chan int, 10)有缓存的 channel 类似一个阻塞队列(采用环形数组实现)。当缓存未满时,向 channel 中发送消息时不会阻塞,当缓存满时,发送操作将被阻塞,直到有其他 goroutine 从中读取消息;相应的,当 channel 中消息不为空时,读取消息不会出现阻塞,当 channel 为空时,读取操作会造成阻塞,直到有 goroutine 向 channel 中写入消息。
ch := make(chan int, 3)
// blocked, read from empty buffered channel
<- chch := make(chan int, 3)
ch <- 1
ch <- 2
ch <- 3
// blocked, send to full buffered channel
ch <- 4通过 len 函数可以获得 chan 中的元素个数,通过 cap 函数可以得到 channel 的缓存长度。
channel 的用法
go匿名函数
三种线程安全的 map
1.加读写锁
常见的 map 的操作有增删改查和遍历,这里面查和遍历是读操作,增删改是写操作,因此对查和遍历需要加读锁,对增删改需要加写锁。
2.分片加锁
通过读写锁 RWMutex 实现的线程安全的 map,功能上已经完全满足了需要,但是面对高并发的场景,仅仅功能满足可不行,性能也得跟上。
**锁是性能下降的万恶之源之一。**所以并发编程的原则就是尽可能减少锁的使用。当锁不得不用的时候,可以减小锁的粒度和持有的时间。
在第一种方法中,加锁的对象是整个 map,协程 A 对 map 中的 key 进行修改操作,会导致其它协程无法对其它 key 进行读写操作。一种解决思路是将这个 map 分成 n 块,每个块之间的读写操作都互不干扰,从而降低冲突的可能性。
3.sync 中的 map
分片加锁的思路是将大块的数据切分成小块的数据,从而减少冲突导致锁阻塞的可能性。如果在一些特殊的场景下,将读写数据分开,是不是能在进一步提升性能呢?
在内置的 sync 包中(Go 1.9+)也有一个线程安全的 map,通过将读写分离的方式实现了某些特定场景下的性能提升。
xml语言
XML的定义
扩展标记语言 (Extensible Markup Language, XML) ,用于标记电子文件使其具有结构性的标记语言,可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。 XML使用DTD(document type definition)文档类型定义来组织数据;格式统一,跨平台和语言,早已成为业界公认的标准。 XML是非常适合 Web 传输。XML 提供统一的方法来描述和交换独立于应用程序或供应商的结构化数据。
XML的特点
- 有且只有一个根节点;
- 数据传输的载体;
- 所有的标签都需要自定义;
- 是纯文本文件
- 格式统一,符合标准;
- 容易与其他系统进行远程交互,数据共享比较方便。
XML的缺点
- XML文件庞大,文件格式复杂,传输占带宽;
- 服务器端和客户端都需要花费大量代码来解析XML,导致服务器端和客户端代码变得异常复杂且不易维护;
- 客户端不同浏览器之间解析XML的方式不一致,需要重复编写很多代码;
- 服务器端和客户端解析XML花费较多的资源和时间。
JSON数据格式
JSON定义 JSON(JavaScript Object Notation)一种轻量级的数据交换格式,具有良好的可读和便于快速编写的特性。可在不同平台之间进行数据交换。JSON采用兼容性很高的、完全独立于语言文本格式,同时也具备类似于C语言的习惯(包括C, C++, C#, Java, JavaScript, Perl, Python等)体系的行为。这些特性使JSON成为理想的数据交换语言。
JSON 特点 数据格式比较简单,易于读写,格式都是压缩的,占用带宽小; 易于解析,客户端JavaScript可以简单的通过eval()进行JSON数据的读取; 支持多种语言,包括ActionScript, C, C#, ColdFusion, Java, JavaScript, Perl, PHP, Python, Ruby等服务器端语言,便于服务器端的解析; 在PHP世界,已经有PHP-JSON和JSON-PHP出现了,偏于PHP序列化后的程序直接调用,PHP服务器端的对象、数组等能直接生成JSON格式,便于客户端的访问提取; 因为JSON格式能直接为服务器端代码使用,大大简化了服务器端和客户端的代码开发量,且完成任务不变,并且易于维护。
2.3 JSON缺点 没有XML格式这么推广的深入人心和喜用广泛,没有XML那么通用性; JSON格式目前在Web Service中应用不广泛。
XML和JSON的优缺点对比
- 可读性方面。 JSON和XML的数据可读性基本相同,JSON和XML的可读性可谓不相上下,一边是建议的语法,一边是规范的标签形式,XML可读性较好些。
- 可扩展性方面。 XML天生有很好的扩展性,JSON当然也有,没有什么是XML能扩展,JSON不能的。
- 编码难度方面。 XML有丰富的编码工具,比如Dom4j、JDom等,JSON也有json.org提供的工具,但是JSON的编码明显比XML容易许多,即使不借助工具也能写出JSON的代码,可是要写好XML就不太容易了。
- 解码难度方面。 XML的解析得考虑子节点父节点,让人头昏眼花,而JSON的解析难度几乎为0。这一点XML输的真是没话说。
- 解析手段方面。 JSON和XML同样拥有丰富的解析手段。
- 数据体积方面。 JSON相对于XML来讲,数据的体积小,传递的速度更快些。
- 数据交互方面。 JSON与JavaScript的交互更加方便,更容易解析处理,更好的数据交互。
- 数据描述方面。 JSON对数据的描述性比XML较差。
- 传输速度方面。 JSON的速度要远远快于XML。
编码的可读性来说,XML有明显的优势,毕竟人类的语言更贴近这样的说明结构。JSON读起来更像一个数据块,读起来就比较费解了。不过,我们读起来费解的语言,恰恰是适合机器阅读,所以通过JSON的索引country.provinces[0].name就能够读取“黑龙江”这个值。 编码的手写难度来说,XML还是舒服一些,好读当然就好写。不过写出来的字符JSON就明显少很多。去掉空白制表以及换行的话,JSON就是密密麻麻的有用数据,而XML却包含很多重复的标记字符。
算法与数据结构
堆和栈的区别(数据结构)
栈就像装数据的桶或箱子,后进先出。
堆像一棵倒过来的树,经过排序的树形数据结构,每个结点都有一个值,通常我们所说的堆的数据结构,是指二叉堆。
栈和堆的区别(内存分配)
-
管理方式不同。栈由操作系统自动分配释放,无需我们手动控制;堆的申请和释放工作由程序员控制,容易产生内存泄漏;
-
空间大小不同。每个进程拥有的栈的大小要远远小于堆的大小。理论上,程序员可申请的堆大小为虚拟内存的大小,进程栈的大小 64bits 的 Windows 默认 1MB,64bits 的 Linux 默认 10MB;
-
生长方向不同。堆的生长方向向上,内存地址由低到高;栈的生长方向向下,内存地址由高到低。
-
分配方式不同。堆都是动态分配的,没有静态分配的堆。栈有2种分配方式:静态分配和动态分配。静态分配是由操作系统完成的,比如局部变量的分配。动态分配由alloca函数进行分配,但是栈的动态分配和堆是不同的,他的动态分配是由操作系统进行释放,无需我们手工实现。
-
分配效率不同。栈由操作系统自动分配,会在硬件层级对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高。堆则是由C/C++提供的库函数或运算符来完成申请与管理,实现机制较为复杂,频繁的内存申请容易产生内存碎片。显然,堆的效率比栈要低得多。
-
存放内容不同。栈存放的内容,函数返回地址、相关参数、局部变量和寄存器内容等。堆,一般情况堆顶使用一个字节的空间来存放堆的大小,而堆中具体存放内容是由程序员来填充的。
使用栈就象我们去饭馆里吃饭,只管点菜(发出申请)、付钱、和吃(使用),吃饱了就走,不必理会切菜、洗菜等准备工作和洗碗、刷锅等扫尾工作,他的好处是快捷,但是自由度小。
使用堆就象是自己动手做喜欢吃的菜肴,比较麻烦,但是比较符合自己的口味,而且自由度大。比喻很形象,说的很通俗易懂,不知道你是否有点收获。
数组和链表的区别
数组与链表是数据存储方式的概念,数组在连续的空间中存储数据,而链表可以在非连续的空间中存储数据;
数组静态分配内存,链表动态分配内存;数组在内存中连续,链表不连续;数组利用下标定位,时间复杂度为O(1),链表定位元素时间复杂度O(n);数组插入或删除元素的时间复杂度O(n),链表的时间复杂度O(1)。
根据以上分析可得出数组和链表的优缺点如下:
数组的优点 随机访问性强(通过下标进行快速定位) 查找速度快 数组的缺点 插入和删除效率低(插入和删除需要移动数据) 可能浪费内存(因为是连续的,所以每次申请数组之前必须规定数组的大小,如果大小不合理,则可能会浪费内存) 内存空间要求高,必须有足够的连续内存空间。 数组大小固定,不能动态拓展 链表的优点 插入删除速度快(因为有next指针指向其下一个节点,通过改变指针的指向可以方便的增加删除元素) 内存利用率高,不会浪费内存(可以使用内存中细小的不连续空间(大于node节点的大小),并且在需要空间的时候才创建空间) 大小没有固定,拓展很灵活。 链表的缺点 不能随机查找,必须从第一个开始遍历,查找效率低
单链表和双链表
单链表只有一个指向下一结点的指针,也就是只能next 双链表除了有一个指向下一结点的指针外,还有一个指向前一结点的指针,可以通过prev()快速找到前一结点,顾名思义,单链表只能单向读取。
双链表的在查找、删除的时候可以利用二分法的思想去实现,那么这样效率就会大大提高,但是为什么目前市场应用上单链表的应用要比双链表的应用要广泛的多呢?
从以上结构可以得出双链表具有以下优点:
1、删除单链表中的某个结点时,一定要得到待删除结点的前驱,得到该前驱有两种方法,第一种方法是在定位待删除结点的同时一路保存当前结点的前驱。第二种方法是在定位到待删除结点之后,重新从单链表表头开始来定位前驱。尽管通常会采用方法一。但其实这两种方法的效率是一样的,指针的总的移动操作都会有2*i次。而如果用双向链表,则不需要定位前驱结点。因此指针总的移动操作为i次。
2、查找时也一样,我们可以借用二分法的思路,从head(首节点)向后查找操作和last(尾节点)向前查找操作同步进行,这样双链表的效率可以提高一倍。
可是为什么市场上单链表的使用多余双链表呢?
从存储结构来看,每个双链表的节点要比单链表的节点多一个指针,而长度为n就需要 n*length(这个指针的length在32位系统中是4字节,在64位系统中是8个字节) 的空间,这在一些追求时间效率不高应用下并不适应,因为它占用空间大于单链表所占用的空间;这时设计者就会采用以时间换空间的做法,这时一种工程总体上的衡量。
队列和堆栈区别
队列和堆栈是描述数据存取方式的概念,队列是先进先出,而堆栈是后进先出;队列和堆栈可以用数组来实现,也可以用链表实现。
树
红黑树和AVL树的区别
红黑树:一种平衡二叉树,但每个节点有一个存储位表示节点的颜色,可以是红或黑。通过对任何一条从根到叶子的路径上各个节点着色的方式的限制,红黑树确保没有一条路径会比其它路径长出两倍,因此,红黑树是一种弱平衡二叉树(由于是弱平衡,可以看到,在相同的节点情况下,AVL树的高度<=红黑树),相对于要求严格的AVL树来说,它的旋转次数少,所以对于搜索,插入,删除操作较多的情况下,用红黑树。
- 每个节点非红即黑
- 根节点是黑的;
- 每个叶节点(叶节点即树尾端NULL指针或NULL节点)都是黑的;
- 如果一个节点是红的,那么它的两儿子都是黑的;
- 对于任意节点而言,其到叶子点树NULL指针的每条路径都包含相同数目的黑节点;
- 每条路径都包含相同的黑节点;
| 平衡二叉树类型 | 平衡度 | 调整频率 | 适用场景 |
|---|---|---|---|
| AVL树 | 高 | 高 | 查询多,增/删少 |
| 红黑树 | 低 | 低 | 增/删频繁 |
哈希(散列)表
散列表用的是数组支持按照下标随机访问数据的特性,所以散列表其实就是数组的一种扩展,由数组演化而来。可以说,如果没有数组,就没有散列表。
哈希冲突
哈希是通过对数据进行再压缩,提高效率的一种解决方法。但由于通过哈希函数产生的哈希值是有限的,而数据可能比较多,导致经过哈希函数处理后仍然有不同的数据对应相同的值。这时候就产生了哈希冲突。
产生哈希冲突的影响因素 装填因子(装填因子=数据总数 / 哈希表长)、哈希函数、处理冲突的方法
解决哈希冲突的四种方法 1.开放地址方法
(1)线性探测
按顺序决定值时,如果某数据的值已经存在,则在原来值的基础上往后加一个单位,直至不发生哈希冲突。
(2)再平方探测
按顺序决定值时,如果某数据的值已经存在,则在原来值的基础上先加1的平方个单位,若仍然存在则减1的平方个单位。随之是2的平方,3的平方等等。直至不发生哈希冲突。
(3)伪随机探测
按顺序决定值时,如果某数据已经存在,通过随机函数随机生成一个数,在原来值的基础上加上随机数,直至不发生哈希冲突。
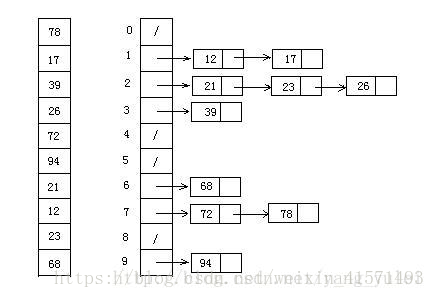
2.链式地址法(HashMap的哈希冲突解决方法)
对于相同的值,使用链表进行连接。使用数组存储每一个链表。
优点:
(1)拉链法处理冲突简单,且无堆积现象,即非同义词决不会发生冲突,因此平均查找长度较短;
(2)由于拉链法中各链表上的结点空间是动态申请的,故它更适合于造表前无法确定表长的情况;
(3)开放定址法为减少冲突,要求装填因子α较小,故当结点规模较大时会浪费很多空间。而拉链法中可取α≥1,且结点较大时,拉链法中增加的指针域可忽略不计,因此节省空间;
(4)在用拉链法构造的散列表中,删除结点的操作易于实现。只要简单地删去链表上相应的结点即可。 缺点:
指针占用较大空间时,会造成空间浪费,若空间用于增大散列表规模进而提高开放地址法的效率。
3.建立公共溢出区
建立公共溢出区存储所有哈希冲突的数据。
4.再哈希法
对于冲突的哈希值再次进行哈希处理,直至没有哈希冲突。
排序算法
算法分类
十种常见排序算法可以分为两大类:
非线性时间比较类排序:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn),因此称为非线性时间比较类排序。
线性时间非比较类排序:不通过比较来决定元素间的相对次序,它可以突破基于比较排序的时间下界,以线性时间运行,因此称为线性时间非比较类排序。

- 稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面。
- 不稳定:如果a原本在b的前面,而a=b,排序之后 a 可能会出现在 b 的后面。
- 时间复杂度:对排序数据的总的操作次数。反映当n变化时,操作次数呈现什么规律。
- 空间复杂度:是指算法在计算机内执行时所需存储空间的度量,它也是数据规模n的函数。
交换排序
冒泡排序
- 比较相邻的元素。如果第一个比第二个大,就交换它们两个;
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数;
- 针对所有的元素重复以上的步骤,除了最后一个;
- 重复步骤1~3,直到排序完成。
冒泡排序对n个数据操作n-1轮,每轮找出一个最大(小)值。
操作只对相邻两个数比较与交换,每轮会将一个最值交换到数据列首(尾),像冒泡一样。
每轮操作O(n)次,共O(n)轮,时间复杂度O(n^2)。
额外空间开销出在交换数据时那一个过渡空间,空间复杂度O(1)
代码:
import random
def randomList(n):
iList = []
for i in range(n):
iList.append(random.randrange(1000)) # append()函数用于产生随机数存入iList列表中
return iList
iList1=randomList(20)
def bubbleSort(iList):
"""冒泡排序"""
if len(iList1) <=1:
return iList1
for i in range(1,len(iList1)):
for j in range(0,len(iList1)-i):
if iList[j] >= iList[j+1]:
iList1[j], iList1[j+1] = iList1[j+1], iList1[j]
print("第%d轮排序结果为:" %i, end=" ")
print(iList1)
return iList
if __name__ == "__main__":
print(iList1)
print("冒泡排序结果:",bubbleSort(iList1))快速排序
- 从数列中挑出一个元素,称为 “基准”(pivot);
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
快速排序基于选择划分,是简单选择排序的优化。
每次划分将数据选到基准值两边,循环对两边的数据进行划分,类似于二分法。
算法的整体性能取决于划分的平均程度,即基准值的选择,此处衍生出快速排序的许多优化方案,甚至可以划分为多块。
基准值若能把数据分为平均的两块,划分次数O(logn),每次划分遍历比较一遍O(n),时间复杂度O(nlogn)。
额外空间开销出在暂存基准值,O(logn)次划分需要O(logn)个,空间复杂度O(logn)
代码:
import random
import timeit
import sys
sys.setrecursionlimit(10000)
def randomList(n):
iList = []
for i in range(n):
iList.append(random.randrange(1000)) # append()函数用于产生随机数存入iList列表中
return iList
iList=randomList(20)
def quickSort(iList):
if len(iList) <= 1:
return iList
left = []
right = []
for i in iList[1:]:
if i <= iList[0]:
left.append(i)
else:
right.append(i)
return quickSort(left) + [iList[0]] + quickSort(right)
if __name__ == "__main__":
print("排序前随机序列",iList)
print("快速排列后:",quickSort(iList))
print("运行程序所花的时间",timeit.timeit("quickSort(iList)","from __main__ import quickSort,iList",number=100))插入排序
简单插入排序
- 从第一个元素开始,该元素可以认为已经被排序;
- 取出下一个元素,在已经排序的元素序列中从后向前扫描;
- 如果该元素(已排序)大于新元素,将该元素移到下一位置;
- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置;
- 将新元素插入到该位置后;
- 重复步骤2~5。
简单插入排序同样操作n-1轮,每轮将一个未排序树插入排好序列。
开始时默认第一个数有序,将剩余n-1个数逐个插入。插入操作具体包括:比较确定插入位置,数据移位腾出合适空位
每轮操作O(n)次,共O(n)轮,时间复杂度O(n^2)。
额外空间开销出在数据移位时那一个过渡空间,空间复杂度O(1)。
代码:
import random
def randomList(n):
iList = []
for i in range(n):
iList.append(random.randrange(1000))
return iList
iList1=randomList(20)
def insertionSort(iList):
if len(iList1) <= 1:
return iList1
for right in range(1, len(iList1)):
target = iList1[right]
for left in range(0, right):
if target <= iList1[left]:
iList1[left+1:right+1] = iList1[left:right] # 使用python的切片赋值
iList1[left] = target
break
print("第%d轮排序结果:" %(right), end=" ")
print(iList1)
return iList1
if __name__ == "__main__":
print(iList1)
print("插入排序后的结果:",insertionSort(iList1))希尔排序(Shell Sort)
先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,具体算法描述:
- 选择一个增量序列t1,t2,…,tk,其中ti>tj,tk=1;
- 按增量序列个数k,对序列进行k 趟排序;
- 每趟排序,根据对应的增量ti,将待排序列分割成若干长度为m 的子序列,分别对各子表进行直接插入排序。仅增量因子为1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
希尔排序是插入排序的高效实现(大家可以比对一下插入排序和希尔排序的代码),对简单插入排序减少移动次数优化而来。
简单插入排序每次插入都要移动大量数据,前后插入时的许多移动都是重复操作,若一步到位移动效率会高很多。
若序列基本有序,简单插入排序不必做很多移动操作,效率很高。
希尔排序将序列按固定间隔划分为多个子序列,在子序列中简单插入排序,先做远距离移动使序列基本有序;逐渐缩小间隔重复操作,最后间隔为1时即简单插入排序。
希尔排序对序列划分O(n)次,每次简单插入排序O(logn),时间复杂度O(nlogn)
额外空间开销出在插入过程数据移动需要的一个暂存,空间复杂度O(1)

def ShellSort(lst):
def shellinsert(arr,d):
n=len(arr)
for i in range(d,n):
j=i-d
temp=arr[i] #记录要出入的数
while(j>=0 and arr[j]>temp): #从后向前,找打比其小的数的位置
arr[j+d]=arr[j] #向后挪动
j-=d
if j!=i-d:
arr[j+d]=temp
n=len(lst)
if n<=1:
return lst
d=n//2
while d>=1:
shellinsert(lst,d)
d=d//2
return lst
x=input("请输入待排序数列:\n")
y=x.split()
arr=[]
for i in y:
arr.append(int(i))
arr=ShellSort(arr)
print(arr)
print("数列按序排列如下:")
for i in arr:
print(i,end=' ') 选择排序
简单选择排序(Select Sort)
- 初始状态:无序区为R[1..n],有序区为空;
- 第i趟排序(i=1,2,3…n-1)开始时,当前有序区和无序区分别为R[1..i-1]和R(i..n)。该趟排序从当前无序区中-选出关键字最小的记录 R[k],将它与无序区的第1个记录R交换,使R[1..i]和R[i+1..n)分别变为记录个数增加1个的新有序区和记录个数减少1个的新无序区;
- n-1趟结束,数组有序化了。
简单选择排序同样对数据操作n-1轮,每轮找出一个最大(小)值。
操作指选择,即未排序数逐个比较交换,争夺最值位置,每轮将一个未排序位置上的数交换成已排序数,即每轮选一个最值。
每轮操作O(n)次,共O(n)轮,时间复杂度O(n^2)。
额外空间开销出在交换数据时那一个过渡空间,空间复杂度O(1)。
代码:
import random
def randomList(n):
iList = []
for i in range(n):
iList.append(random.randrange(1000))
return iList
iList1=randomList(20)
def selectionSort(iList):
if len(iList1) <= 1:
return iList1
for i in range(0,len(iList1)-1):
if iList1[i] !=min(iList1[i:]): # 使用min函数找到剩余数列中最小的那个数
minIndex = iList.index(min(iList1[i:]))
iList1[i], iList1[minIndex] = iList1[minIndex], iList1[i]
print("第%d轮排序结果:" %(i+1), end=" ")
print(iList1)
return iList1
if __name__ == "__main__":
print(iList1)
print("选择排序以后的结果:", selectionSort(iList1))堆排序(Heap Sort)
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
- 将初始待排序关键字序列(R1,R2….Rn)构建成大顶堆,此堆为初始的无序区;
- 将堆顶元素R[1]与最后一个元素R[n]交换,此时得到新的无序区(R1,R2,……Rn-1)和新的有序区(Rn),且满足R[1,2…n-1]<=R[n];
- 由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1,R2,……Rn-1)调整为新堆,然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1,R2….Rn-2)和新的有序区(Rn-1,Rn)。不断重复此过程直到有序区的元素个数为n-1,则整个排序过程完成。
堆排序的初始建堆过程比价复杂,对O(n)级别个非叶子节点进行堆调整操作O(logn),时间复杂度O(nlogn);之后每一次堆调整操作确定一个数的次序,时间复杂度O(nlogn)。合起来时间复杂度O(nlogn)
额外空间开销出在调整堆过程,根节点下移交换时一个暂存空间,空间复杂度O(1)

def MergeSort(lst):
#合并左右子序列函数
def merge(arr,left,mid,right):
temp=[] #中间数组
i=left #左段子序列起始
j=mid+1 #右段子序列起始
while i<=mid and j<=right:
if arr[i]<=arr[j]:
temp.append(arr[i])
i+=1
else:
temp.append(arr[j])
j+=1
while i<=mid:
temp.append(arr[i])
i+=1
while j<=right:
temp.append(arr[j])
j+=1
for i in range(left,right+1): # !注意这里,不能直接arr=temp,他俩大小都不一定一样
arr[i]=temp[i-left]
#递归调用归并排序
def mSort(arr,left,right):
if left>=right:
return
mid=(left+right)//2
mSort(arr,left,mid)
mSort(arr,mid+1,right)
merge(arr,left,mid,right)
n=len(lst)
if n<=1:
return lst
mSort(lst,0,n-1)
return lst
x=input("请输入待排序数列:\n")
y=x.split()
arr=[]
for i in y:
arr.append(int(i))
arr=MergeSort(arr)
#print(arr)
print("数列按序排列如下:")
for i in arr:
print(i,end=' ')
归并排序
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2-路归并。
- 把长度为n的输入序列分成两个长度为n/2的子序列;
- 对这两个子序列分别采用归并排序;
- 将两个排序好的子序列合并成一个最终的排序序列。
代码:
import random
import sys
import timeit
sys.setrecursionlimit(10000)
def randomList(n):
iList = []
for i in range(n):
iList.append(random.randrange(1000))
return iList
iList=randomList(20)
def mergeSort(iList):
if len(iList) <= 1:
return iList
middle = len(iList)//2
left,right = iList[0:middle],iList[middle:]
return mergeList(mergeSort(left), mergeSort(right))
def mergeList(left,right):
mList = []
while left and right:
if left[0] >= right[0]:
mList.append(right.pop(0))
else:
mList.append(left.pop(0))
while left:
mList.append(left.pop(0))
while right:
mList.append(right.pop(0))
return mList
if __name__ =="__main__":
print(iList)
print("排序后的结果:",mergeSort(iList))
print(timeit.timeit("mergeSort(iList)","from __main__ import mergeSort,iList",number=100))归并排序是一种稳定的排序方法。和选择排序一样,归并排序的性能不受输入数据的影响,但表现比选择排序好的多,因为始终都是O(nlogn)的时间复杂度。代价是需要额外的内存空间。
线性时间非比较类排序
5.1 计数排序(Counting Sort)
- 找出待排序的数组中最大和最小的元素;
- 统计数组中每个值为i的元素出现的次数,存入数组C的第i项;
- 对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加);
- 反向填充目标数组:将每个元素i放在新数组的第C(i)项,每放一个元素就将C(i)减去1。
计数排序用待排序的数值作为计数数组(列表)的下标,统计每个数值的个数,然后依次输出即可。
计数数组的大小取决于待排数据取值范围,所以对数据有一定要求,否则空间开销无法承受。
计数排序只需遍历一次数据,在计数数组中记录,输出计数数组中有记录的下标,时间复杂度为O(n+k)。
额外空间开销即指计数数组,实际上按数据值分为k类(大小取决于数据取值),空间复杂度O(k)。

def CountSort(lst):
n=len(lst)
num=max(lst)
count=[0]*(num+1)
for i in range(0,n):
count[lst[i]]+=1
arr=[]
for i in range(0,num+1):
for j in range(0,count[i]):
arr.append(i)
return arr
x=input("请输入待排序数列:\n")
y=x.split()
arr=[]
for i in y:
arr.append(int(i))
arr=CountSort(arr)
print(arr)
print("数列按序排列如下:")
for i in arr:
print(i,end=' ') 计数排序是一个稳定的排序算法。当输入的元素是 n 个 0到 k 之间的整数时,时间复杂度是O(n+k),空间复杂度也是O(n+k),其排序速度快于任何比较排序算法。当k不是很大并且序列比较集中时,计数排序是一个很有效的排序算法。
5.2 桶排序(Bucket Sort)
- 设置一个定量的数组当作空桶;
- 遍历输入数据,并且把数据一个一个放到对应的桶里去;
- 对每个不是空的桶进行排序;
- 从不是空的桶里把排好序的数据拼接起来。
桶排序实际上是计数排序的推广,但实现上要复杂许多。
桶排序先用一定的函数关系将数据划分到不同有序的区域(桶)内,然后子数据分别在桶内排序,之后顺次输出。
当每一个不同数据分配一个桶时,也就相当于计数排序。
假设n个数据,划分为k个桶,桶内采用快速排序,时间复杂度为O(n)+O(k * n/klog(n/k))=O(n)+O(n(log(n)-log(k))),
显然,k越大,时间复杂度越接近O(n),当然空间复杂度O(n+k)会越大,这是空间与时间的平衡。
def BucketSort(lst):
##############桶内使用快速排序
def QuickSort(lst):
def partition(arr,left,right):
key=left #划分参考数索引,默认为第一个数,可优化
while left<right:
while left<right and arr[right]>=arr[key]:
right-=1
while left<right and arr[left]<=arr[key]:
left+=1
(arr[left],arr[right])=(arr[right],arr[left])
(arr[left],arr[key])=(arr[key],arr[left])
return left
def quicksort(arr,left,right): #递归调用
if left>=right:
return
mid=partition(arr,left,right)
quicksort(arr,left,mid-1)
quicksort(arr,mid+1,right)
#主函数
n=len(lst)
if n<=1:
return lst
quicksort(lst,0,n-1)
return lst
######################
n=len(lst)
big=max(lst)
num=big//10+1
bucket=[]
buckets=[[] for i in range(0,num)]
for i in lst:
buckets[i//10].append(i) #划分桶
for i in buckets: #桶内排序
bucket=QuickSort(i)
arr=[]
for i in buckets:
if isinstance(i, list):
for j in i:
arr.append(j)
else:
arr.append(i)
for i in range(0,n):
lst[i]=arr[i]
return lst
x=input("请输入待排序数列:\n")
y=x.split()
arr=[]
for i in y:
arr.append(int(i))
arr=BucketSort(arr)
#print(arr)
print("数列按序排列如下:")
for i in arr:
print(i,end=' ')
桶排序最好情况下使用线性时间O(n),桶排序的时间复杂度,取决与对各个桶之间数据进行排序的时间复杂度,因为其它部分的时间复杂度都为O(n)。很显然,桶划分的越小,各个桶之间的数据越少,排序所用的时间也会越少。但相应的空间消耗就会增大。5.3 基数排序(Radix Sort)
- 取得数组中的最大数,并取得位数;
- arr为原始数组,从最低位开始取每个位组成radix数组;
- 对radix进行计数排序(利用计数排序适用于小范围数的特点);

import math
def RadixSort(lst):
def getbit(x,i): #返回x的第i位(从右向左,个位为0)数值
y=x//pow(10,i)
z=y%10
return z
def CountSort(lst):
n=len(lst)
num=max(lst)
count=[0]*(num+1)
for i in range(0,n):
count[lst[i]]+=1
arr=[]
for i in range(0,num+1):
for j in range(0,count[i]):
arr.append(i)
return arr
Max=max(lst)
for k in range(0,int(math.log10(Max))+1): #对k位数排k次,每次按某一位来排
arr=[[] for i in range(0,10)]
for i in lst: #将ls(待排数列)中每个数按某一位分类(0-9共10类)存到arr[][]二维数组(列表)中
arr[getbit(i,k)].append(i)
for i in range(0,10): #对arr[]中每一类(一个列表) 按计数排序排好
if len(arr[i])>0:
arr[i]=CountSort(arr[i])
j=9
n=len(lst)
for i in range(0,n): #顺序输出arr[][]中数到ls中,即按第k位排好
while len(arr[j])==0:
j-=1
else:
ls[n-1-i]=arr[j].pop()
return lst
x=input("请输入待排序数列:\n")
y=x.split()
arr=[]
for i in y:
arr.append(int(i))
arr=RadixSort(arr)
print(arr)
print("数列按序排列如下:")
for i in arr:
print(i,end=' ') 基数排序基于分别排序,分别收集,所以是稳定的。但基数排序的性能比桶排序要略差,每一次关键字的桶分配都需要O(n)的时间复杂度,而且分配之后得到新的关键字序列又需要O(n)的时间复杂度。假如待排数据可以分为d个关键字,则基数排序的时间复杂度将是O(d*2n) ,当然d要远远小于n,因此基本上还是线性级别的。
基数排序的空间复杂度为O(n+k),其中k为桶的数量。一般来说n>>k,因此额外空间需要大概n个左右。
查找算法
顺序查找
算法简介:顺序查找又称线性查找,是一种最简单的查找方法;适用于线性表的顺序村粗结构和链式存储结构;算法的时间复杂度为 𝑂(𝑛)
基本思路:从第一个元素m开始逐个与需要查找的元素x进行比较,当比较到元素值相同(即m=x)时返回元素m的下标,如果比较到最后都没有找到,则返回-1。
- **优点:**对表中数据存储没有要求。另外,对于线性链表,只能进行顺序查找;
- **缺点:**当n很大时,平均查找长度较大,效率低;
算法实现
# 最基础的遍历无序列表的查找算法
# 时间复杂度O(n)
def sequential_search(lis, key):
length = len(lis)
for i in range(length):
if lis[i] == key:
return i
return False
if __name__ == '__main__':
LIST = [1, 5, 8, 123, 22, 54, 7, 99, 300, 222]
result = sequential_search(LIST, 123)
print(result)二分查找
算法简介:二分查找(Binary Search),是一种在有序数组中查找某一特定元素的查找算法。查找过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则查找过程结束;如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较。如果在某一步骤数组为空,则代表找不到。 这种查找算法每一次比较都使查找范围缩小一半。
算法描述
-
给予一个包含n个带值元素的数组A
-
令 L为0 , R为 n-1
-
如果L>R,则搜索以失败告终
-
令 m (中间值元素)为 ⌊(L+R)/2⌋
-
如果 Am<T,令 L为 m + 1 并回到2
-
如果 Am>T,令 R为 m - 1 并回到2
时间复杂度:折半搜索每次把搜索区域减少一半,时间复杂度为 O(logn)
空间复杂度:O(1)
算法实现
# 针对有序查找表的二分查找算法
def binary_search(list, key):
low = 0
high = len(list) - 1
time = 0
while low <= high:
time += 1
mid = int((low + high) / 2)
if key < list[mid]:# 元素小于中间位置的元素,只需要再比较左边的元素
high = mid - 1
elif key > list[mid]:# 元素大于中间位置的元素,只需要再比较右边的元素
low = mid + 1
else: # 元素正好在中间位置
# 打印折半的次数
print("times: %s" % time)
return mid
print("times: %s" % time)
return False
if __name__ == '__main__':
LIST = [1, 5, 7, 8, 22, 54, 99, 123, 200, 222, 444]
result = binary_search(LIST, 99)
print(result)插值查找
算法简介
插值查找是根据要查找的关键字key与查找表中最大最小记录的关键字比较后的 查找方法,其核心就在于插值的计算公式 (key-a[low])/(a[high]-a[low])*(high-low)。 时间复杂度o(logn)但对于表长较大而关键字分布比较均匀的查找表来说,效率较高。
算法思想
基于二分查找算法,将查找点的选择改进为自适应选择,可以提高查找效率。当然,差值查找也属于有序查找。 注:对于表长较大,而关键字分布又比较均匀的查找表来说,插值查找算法的平均性能比折半查找要好的多。反之,数组中如果分布非常不均匀,那么插值查找未必是很合适的选择。
时间复杂性:如果元素均匀分布,则O(log log n)),在最坏的情况下可能需要 O(n)。 空间复杂度:O(1)。
算法实现
# 插值查找算法
def binary_search(lis, key):
low = 0
high = len(lis) - 1
time = 0
while low < high:
time += 1
# 计算mid值是插值算法的核心代码
mid = low + int((high - low) * (key - lis[low])/(lis[high] - lis[low]))
print("mid=%s, low=%s, high=%s" % (mid, low, high))
if key < lis[mid]:
high = mid - 1
elif key > lis[mid]:
low = mid + 1
else:
# 打印查找的次数
print("times: %s" % time)
return mid
print("times: %s" % time)
return False
if __name__ == '__main__':
LIST = [1, 5, 7, 8, 22, 54, 99, 123, 200, 222, 444]
result = binary_search(LIST, 444)
print(result)斐波那契查找
算法简介
斐波那契数列,又称黄金分割数列,指的是这样一个数列:1、1、2、3、5、8、13、21、····,在数学上,斐波那契被递归方法如下定义:F(1)=1,F(2)=1,F(n)=f(n-1)+F(n-2) (n>=2)。该数列越往后相邻的两个数的比值越趋向于黄金比例值(0.618)。
算法描述
斐波那契查找就是在二分查找的基础上根据斐波那契数列进行分割的。在斐波那契数列找一个等于略大于查找表中元素个数的数F[n],将原查找表扩展为长度为Fn,完成后进行斐波那契分割,即F[n]个元素分割为前半部分F[n-1]个元素,后半部分F[n-2]个元素,找出要查找的元素在那一部分并递归,直到找到。
最坏情况下,时间复杂度为O(log2n),且其期望复杂度也为O(log2n)。
算法实现
# 斐波那契查找算法
# 时间复杂度O(log(n))
def fibonacci_search(lis, key):
# 需要一个现成的斐波那契列表。其最大元素的值必须超过查找表中元素个数的数值。
F = [1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144,
233, 377, 610, 987, 1597, 2584, 4181, 6765,
10946, 17711, 28657, 46368]
low = 0
high = len(lis) - 1
# 为了使得查找表满足斐波那契特性,在表的最后添加几个同样的值
# 这个值是原查找表的最后那个元素的值
# 添加的个数由F[k]-1-high决定
k = 0
while high > F[k]-1:
k += 1
print(k)
i = high
while F[k]-1 > i:
lis.append(lis[high])
i += 1
print(lis)
# 算法主逻辑。time用于展示循环的次数。
time = 0
while low <= high:
time += 1
# 为了防止F列表下标溢出,设置if和else
if k < 2:
mid = low
else:
mid = low + F[k-1]-1
print("low=%s, mid=%s, high=%s" % (low, mid, high))
if key < lis[mid]:
high = mid - 1
k -= 1
elif key > lis[mid]:
low = mid + 1
k -= 2
else:
if mid <= high:
# 打印查找的次数
print("times: %s" % time)
return mid
else:
print("times: %s" % time)
return high
print("times: %s" % time)
return False
if __name__ == '__main__':
LIST = [1, 5, 7, 8, 22, 54, 99, 123, 200, 222, 444]
result = fibonacci_search(LIST, 444)
print(result)树表查找
二叉树查找
算法简介
二叉查找树是先对待查找的数据进行生成树,确保树的左分支的值小于右分支的值,然后在就行和每个节点的父节点比较大小,查找最适合的范围。 这个算法的查找效率很高,但是如果使用这种查找方法要首先创建树。
算法思想
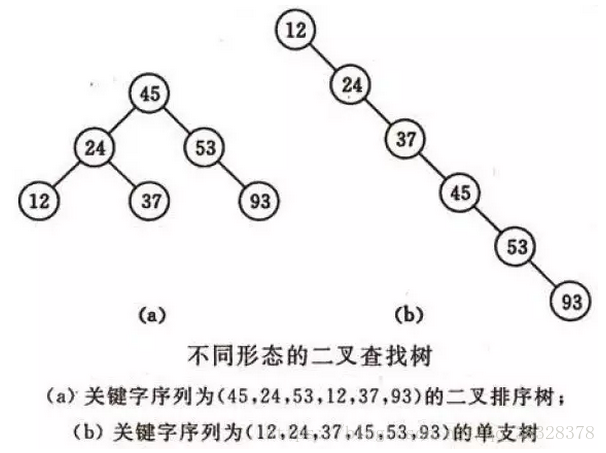
二叉查找树(BinarySearch Tree)或者是一棵空树,或者是具有下列性质的二叉树:
- 若任意节点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 任意节点的左、右子树也分别为二叉查找树。
二叉查找树性质:对二叉查找树进行中序遍历,即可得到有序的数列。
复杂度分析
它和二分查找一样,插入和查找的时间复杂度均为O(logn),但是在最坏的情况下仍然会有O(n)的时间复杂度。原因在于插入和删除元素的时候,树没有保持平衡。
算法实现
# 二叉树查找 Python实现
class BSTNode:
"""
定义一个二叉树节点类。
以讨论算法为主,忽略了一些诸如对数据类型进行判断的问题。
"""
def __init__(self, data, left=None, right=None):
"""
初始化
:param data: 节点储存的数据
:param left: 节点左子树
:param right: 节点右子树
"""
self.data = data
self.left = left
self.right = right
class BinarySortTree:
"""
基于BSTNode类的二叉查找树。维护一个根节点的指针。
"""
def __init__(self):
self._root = None
def is_empty(self):
return self._root is None
def search(self, key):
"""
关键码检索
:param key: 关键码
:return: 查询节点或None
"""
bt = self._root
while bt:
entry = bt.data
if key < entry:
bt = bt.left
elif key > entry:
bt = bt.right
else:
return entry
return None
def insert(self, key):
"""
插入操作
:param key:关键码
:return: 布尔值
"""
bt = self._root
if not bt:
self._root = BSTNode(key)
return
while True:
entry = bt.data
if key < entry:
if bt.left is None:
bt.left = BSTNode(key)
return
bt = bt.left
elif key > entry:
if bt.right is None:
bt.right = BSTNode(key)
return
bt = bt.right
else:
bt.data = key
return
def delete(self, key):
"""
二叉查找树最复杂的方法
:param key: 关键码
:return: 布尔值
"""
p, q = None, self._root # 维持p为q的父节点,用于后面的链接操作
if not q:
print("空树!")
return
while q and q.data != key:
p = q
if key < q.data:
q = q.left
else:
q = q.right
if not q: # 当树中没有关键码key时,结束退出。
return
# 上面已将找到了要删除的节点,用q引用。而p则是q的父节点或者None(q为根节点时)。
if not q.left:
if p is None:
self._root = q.right
elif q is p.left:
p.left = q.right
else:
p.right = q.right
return
# 查找节点q的左子树的最右节点,将q的右子树链接为该节点的右子树
# 该方法可能会增大树的深度,效率并不算高。可以设计其它的方法。
r = q.left
while r.right:
r = r.right
r.right = q.right
if p is None:
self._root = q.left
elif p.left is q:
p.left = q.left
else:
p.right = q.left
def __iter__(self):
"""
实现二叉树的中序遍历算法,
展示我们创建的二叉查找树.
直接使用python内置的列表作为一个栈。
:return: data
"""
stack = []
node = self._root
while node or stack:
while node:
stack.append(node)
node = node.left
node = stack.pop()
yield node.data
node = node.right
if __name__ == '__main__':
lis = [62, 58, 88, 48, 73, 99, 35, 51, 93, 29, 37, 49, 56, 36, 50]
bs_tree = BinarySortTree()
for i in range(len(lis)):
bs_tree.insert(lis[i])
# bs_tree.insert(100)
bs_tree.delete(58)
for i in bs_tree:
print(i, end=" ")
# print("\n", bs_tree.search(4))平衡查找树之2-3查找树(2-3 Tree
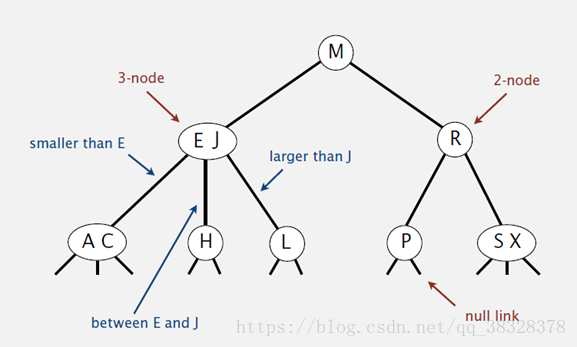
2-3查找树定义
和二叉树不一样,2-3树运行每个节点保存1个或者两个的值。对于普通的2节点(2-node),他保存1个key和左右两个自己点。对应3节点(3-node),保存两个Key,2-3查找树的定义如下: 1)要么为空,要么: 2)对于2节点,该节点保存一个key及对应value,以及两个指向左右节点的节点,左节点也是一个2-3节点,所有的值都比key要小,右节点也是一个2-3节点,所有的值比key要大。 3)对于3节点,该节点保存两个key及对应value,以及三个指向左中右的节点。左节点也是一个2-3节点,所有的值均比两个key中的最小的key还要小;中间节点也是一个2-3节点,中间节点的key值在两个跟节点key值之间;右节点也是一个2-3节点,节点的所有key值比两个key中的最大的key还要大。
2-3查找树的性质
**1)如果中序遍历2-3查找树,就可以得到排好序的序列; 2)在一个完全平衡的2-3查找树中,根节点到每一个为空节点的距离都相同。(这也是平衡树中“平衡”一词的概念,根节点到叶节点的最长距离对应于查找算法的最坏情况,而平衡树中根节点到叶节点的距离都一样,最坏情况也具有对数复杂度。) 2-3树的查找效率与树的高度是息息相关的。
**距离来说,对于1百万个节点的2-3树,树的高度为12-20之间,对于10亿个节点的2-3树,树的高度为18-30之间。 ****
对于插入来说,只需要常数次操作即可完成,因为他只需要修改与该节点关联的节点即可,不需要检查其他节点,所以效率和查找类似。**
算法实现
class Node(object):
def __init__(self,key):
self.key1=key
self.key2=None
self.left=None
self.middle=None
self.right=None
def isLeaf(self):
return self.left is None and self.middle is None and self.right is None
def isFull(self):
return self.key2 is not None
def hasKey(self,key):
if (self.key1==key) or (self.key2 is not None and self.key2==key):
return True
else:
return False
def getChild(self,key):
if key<self.key1:
return self.left
elif self.key2 is None:
return self.middle
elif key<self.key2:
return self.middle
else:
return self.right
class 2_3_Tree(object):
def __init__(self):
self.root=None
def get(self,key):
if self.root is None:
return None
else:
return self._get(self.root,key)
def _get(self,node,key):
if node is None:
return None
elif node.hasKey(key):
return node
else:
child=node.getChild(key)
return self._get(child,key)
def put(self,key):
if self.root is None:
self.root=Node(key)
else:
pKey,pRef=self._put(self.root,key)
if pKey is not None:
newnode=Node(pKey)
newnode.left=self.root
newnode.middle=pRef
self.root=newnode
def _put(self,node,key):
if node.hasKey(key):
return None,None
elif node.isLeaf():
return self._addtoNode(node,key,None)
else:
child=node.getChild(key)
pKey,pRef=self._put(child,key)
if pKey is None:
return None,None
else:
return self._addtoNode(node,pKey,pRef)
def _addtoNode(self,node,key,pRef):
if node.isFull():
return self._splitNode(node,key,pRef)
else:
if key<node.key1:
node.key2=node.key1
node.key1=key
if pRef is not None:
node.right=node.middle
node.middle=pRef
else:
node.key2=key
if pRef is not None:
node.right=Pref
return None,None
def _splitNode(self,node,key,pRef):
newnode=Node(None)
if key<node.key1:
pKey=node.key1
node.key1=key
newnode.key1=node.key2
if pRef is not None:
newnode.left=node.middle
newnode.middle=node.right
node.middle=pRef
elif key<node.key2:
pKey=key
newnode.key1=node.key2
if pRef is not None:
newnode.left=Pref
newnode.middle=node.right
else:
pKey=node.key2
newnode.key1=key
if pRef is not None:
newnode.left=node.right
newnode.middle=pRef
node.key2=None
return pKey,newnode平衡查找树之红黑树
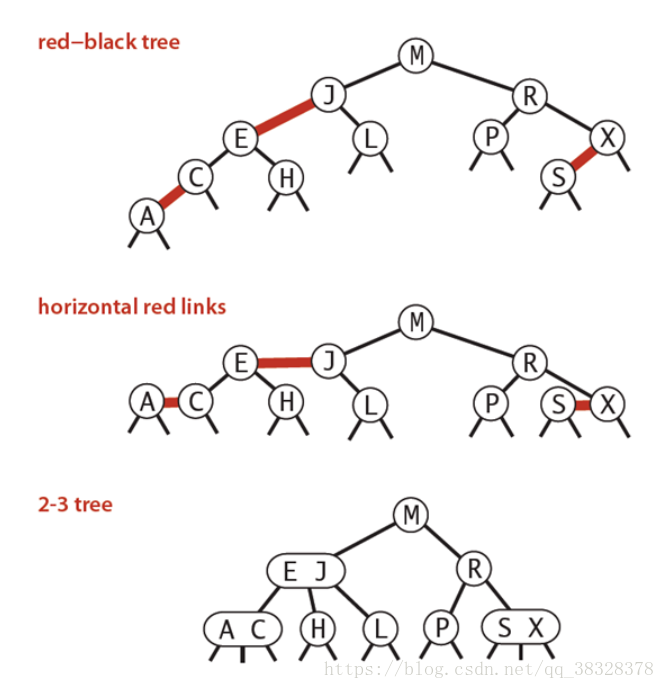
红黑树的定义(Red-Black Tree)
红黑树是一种具有红色和黑色链接的平衡查找树,同时满足: ① 红色节点向左倾斜 ;
②一个节点不可能有两个红色链接;
③整个树完全黑色平衡,即从根节点到所以叶子结点的路径上,黑色链接的个数都相同。
红黑树的性质
整个树完全黑色平衡,即从根节点到所以叶子结点的路径上,黑色链接的个数都相同(2-3树的第2)性质,从根节点到叶子节点的距离都相等)
复杂度分析
最坏的情况就是,红黑树中除了最左侧路径全部是由3-node节点组成,即红黑相间的路径长度是全黑路径长度的2倍。 下图是一个典型的红黑树,从中可以看到最长的路径(红黑相间的路径)是最短路径的2倍:
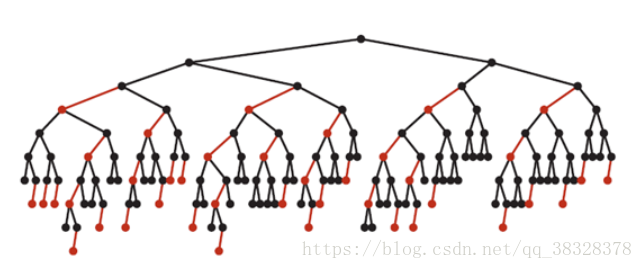
算法实现
#红黑树
from random import randint
RED = 'red'
BLACK = 'black'
class RBT:
def __init__(self):
# self.items = []
self.root = None
self.zlist = []
def LEFT_ROTATE(self, x):
# x是一个RBTnode
y = x.right
if y is None:
# 右节点为空,不旋转
return
else:
beta = y.left
x.right = beta
if beta is not None:
beta.parent = x
p = x.parent
y.parent = p
if p is None:
# x原来是root
self.root = y
elif x == p.left:
p.left = y
else:
p.right = y
y.left = x
x.parent = y
def RIGHT_ROTATE(self, y):
# y是一个节点
x = y.left
if x is None:
# 右节点为空,不旋转
return
else:
beta = x.right
y.left = beta
if beta is not None:
beta.parent = y
p = y.parent
x.parent = p
if p is None:
# y原来是root
self.root = x
elif y == p.left:
p.left = x
else:
p.right = x
x.right = y
y.parent = x
def INSERT(self, val):
z = RBTnode(val)
y = None
x = self.root
while x is not None:
y = x
if z.val < x.val:
x = x.left
else:
x = x.right
z.PAINT(RED)
z.parent = y
if y is None:
# 插入z之前为空的RBT
self.root = z
self.INSERT_FIXUP(z)
return
if z.val < y.val:
y.left = z
else:
y.right = z
if y.color == RED:
# z的父节点y为红色,需要fixup。
# 如果z的父节点y为黑色,则不用调整
self.INSERT_FIXUP(z)
else:
return
def INSERT_FIXUP(self, z):
# case 1:z为root节点
if z.parent is None:
z.PAINT(BLACK)
self.root = z
return
# case 2:z的父节点为黑色
if z.parent.color == BLACK:
# 包括了z处于第二层的情况
# 这里感觉不必要啊。。似乎z.parent为黑色则不会进入fixup阶段
return
# 下面的几种情况,都是z.parent.color == RED:
# 节点y为z的uncle
p = z.parent
g = p.parent # g为x的grandpa
if g is None:
return
# return 这里不能return的。。。
if g.right == p:
y = g.left
else:
y = g.right
# case 3-0:z没有叔叔。即:y为NIL节点
# 注意,此时z的父节点一定是RED
if y == None:
if z == p.right and p == p.parent.left:
# 3-0-0:z为右儿子,且p为左儿子,则把p左旋
# 转化为3-0-1或3-0-2的情况
self.LEFT_ROTATE(p)
p, z = z, p
g = p.parent
elif z == p.left and p == p.parent.right:
self.RIGHT_ROTATE(p)
p, z = z, p
g.PAINT(RED)
p.PAINT(BLACK)
if p == g.left:
# 3-0-1:p为g的左儿子
self.RIGHT_ROTATE(g)
else:
# 3-0-2:p为g的右儿子
self.LEFT_ROTATE(g)
return
# case 3-1:z有黑叔
elif y.color == BLACK:
if p.right == z and p.parent.left == p:
# 3-1-0:z为右儿子,且p为左儿子,则左旋p
# 转化为3-1-1或3-1-2
self.LEFT_ROTATE(p)
p, z = z, p
elif p.left == z and p.parent.right == p:
self.RIGHT_ROTATE(p)
p, z = z, p
p = z.parent
g = p.parent
p.PAINT(BLACK)
g.PAINT(RED)
if p == g.left:
# 3-1-1:p为g的左儿子,则右旋g
self.RIGHT_ROTATE(g)
else:
# 3-1-2:p为g的右儿子,则左旋g
self.LEFT_ROTATE(g)
return
# case 3-2:z有红叔
# 则涂黑父和叔,涂红爷,g作为新的z,递归调用
else:
y.PAINT(BLACK)
p.PAINT(BLACK)
g.PAINT(RED)
new_z = g
self.INSERT_FIXUP(new_z)
def DELETE(self, val):
curNode = self.root
while curNode is not None:
if val < curNode.val:
curNode = curNode.left
elif val > curNode.val:
curNode = curNode.right
else:
# 找到了值为val的元素,正式开始删除
if curNode.left is None and curNode.right is None:
# case1:curNode为叶子节点:直接删除即可
if curNode == self.root:
self.root = None
else:
p = curNode.parent
if curNode == p.left:
p.left = None
else:
p.right = None
elif curNode.left is not None and curNode.right is not None:
sucNode = self.SUCCESOR(curNode)
curNode.val, sucNode.val = sucNode.val, curNode.val
self.DELETE(sucNode.val)
else:
p = curNode.parent
if curNode.left is None:
x = curNode.right
else:
x = curNode.left
if curNode == p.left:
p.left = x
else:
p.right = x
x.parent = p
if curNode.color == BLACK:
self.DELETE_FIXUP(x)
curNode = None
return False
def DELETE_FIXUP(self, x):
p = x.parent
# w:x的兄弟结点
if x == p.left:
w = x.right
else:
w = x.left
# case1:x的兄弟w是红色的
if w.color == RED:
p.PAINT(RED)
w.PAINT(BLACK)
if w == p.right:
self.LEFT_ROTATE(p)
else:
self.RIGHT_ROTATE(p)
if w.color == BLACK:
# case2:x的兄弟w是黑色的,而且w的两个孩子都是黑色的
if w.left.color == BLACK and w.right.color == BLACK:
w.PAINT(RED)
if p.color == BLACK:
return
else:
p.color = BLACK
self.DELETE_FIXUP(p)
# case3:x的兄弟w是黑色的,而且w的左儿子是红色的,右儿子是黑色的
if w.left.color == RED and w.color == BLACK:
w.left.PAINT(BLACK)
w.PAINT(RED)
self.RIGHT_ROTATE(w)
# case4:x的兄弟w是黑色的,而且w的右儿子是红
if w.right.color == RED:
p.PAINT(BLACK)
w.PAINT(RED)
if w == p.right:
self.LEFT_ROTATE(p)
else:
self.RIGHT_ROTATE(p)
def SHOW(self):
self.DISPLAY1(self.root)
return self.zlist
def DISPLAY1(self, node):
if node is None:
return
self.DISPLAY1(node.left)
self.zlist.append(node.val)
self.DISPLAY1(node.right)
def DISPLAY2(self, node):
if node is None:
return
self.DISPLAY2(node.left)
print(node.val)
self.DISPLAY2(node.right)
def DISPLAY3(self, node):
if node is None:
return
self.DISPLAY3(node.left)
self.DISPLAY3(node.right)
print(node.val)
class RBTnode:
'''红黑树的节点类型'''
def __init__(self, val):
self.val = val
self.left = None
self.right = None
self.parent = None
def PAINT(self, color):
self.color = color
def zuoxuan(b, c):
a = b.parent
a.left = c
c.parent = a
b.parent = c
c.left = b
if __name__ == '__main__':
rbt=RBT()
b = []
for i in range(100):
m = randint(0, 500)
rbt.INSERT(m)
b.append(m)
a = rbt.SHOW()
b.sort()
equal = True
for i in range(100):
if a[i] != b[i]:
equal = False
break
if not equal:
print('wrong')
else:
print('OK!')B树和B+树(B Tree/B+ Tree)
B树简介
- B 树可以看作是对2-3查找树的一种扩展,即他允许每个节点有M-1个子节点。
- 根节点至少有两个子节点;
- 每个节点有M-1个key,并且以升序排列;
- 位于M-1和M key的子节点的值位于M-1 和M key对应的Value之间;
- 非叶子结点的关键字个数=指向儿子的指针个数-1;
- 非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] ;
- 其它节点至少有M/2个子节点;
- 所有叶子结点位于同一层; 如:(M=3)
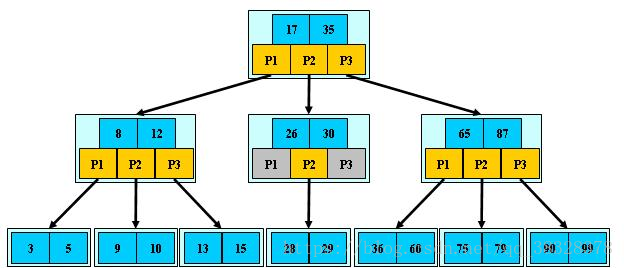
B树算法思想
B-树的搜索,从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果命中则结束,否则进入查询关键字所属范围的儿子结点;重复,直到所对应的儿子指针为空,或已经是叶子结点;
B树的特性
1.关键字集合分布在整颗树中; 2.任何一个关键字出现且只出现在一个结点中; 3.搜索有可能在非叶子结点结束; 4.其搜索性能等价于在关键字全集内做一次二分查找; 5.自动层次控制; 由于限制了除根结点以外的非叶子结点,至少含有M/2个儿子,确保了结点的至少利用率,其最底搜索性能为O(LogN)
B+ 树简介
**B+树是B-树的变体,也是一种多路搜索树: 1.其定义基本与B-树同,除了: 2.非叶子结点的子树指针与关键字个数相同; 3.非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树 4.B-树是开区间; 5.为所有叶子结点增加一个链指针; 6.所有关键字都在叶子结点出现;
**
如:(M=3)
**
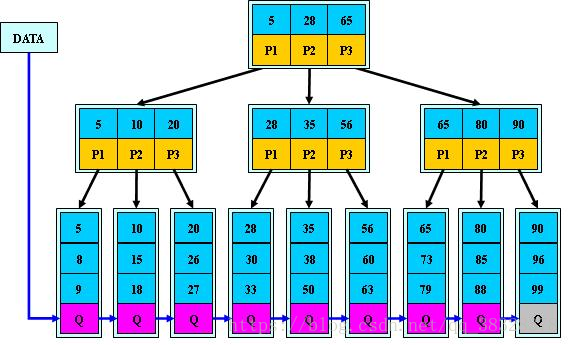
**
B+树算法思想
**B+的搜索与B-树也基本相同,区别是B+树只有达到叶子结点才命中(B-树可以在非叶子结点命中),其性能也等价于在关键字全集做一次二分查找;
**
B+树的特性
1.所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的; 2.不可能在非叶子结点命中; 3.非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层; 4.更适合文件索引系统;
算法实现
# -*- coding: UTF-8 -*-
# B树查找
class BTree: #B树
def __init__(self,value):
self.left=None
self.data=value
self.right=None
def insertLeft(self,value):
self.left=BTree(value)
return self.left
def insertRight(self,value):
self.right=BTree(value)
return self.right
def show(self):
print(self.data)
def inorder(node): #中序遍历:先左子树,再根节点,再右子树
if node.data:
if node.left:
inorder(node.left)
node.show()
if node.right:
inorder(node.right)
def rinorder(node): #倒中序遍历
if node.data:
if node.right:
rinorder(node.right)
node.show()
if node.left:
rinorder(node.left)
def insert(node,value):
if value > node.data:
if node.right:
insert(node.right,value)
else:
node.insertRight(value)
else:
if node.left:
insert(node.left,value)
else:
node.insertLeft(value)
if __name__ == "__main__":
l=[88,11,2,33,22,4,55,33,221,34]
Root=BTree(l[0])
node=Root
for i in range(1,len(l)):
insert(Root,l[i])
print("中序遍历(从小到大排序 )")
inorder(Root)
print("倒中序遍历(从大到小排序)")
rinorder(Root)树表查找总结
二叉查找树平均查找性能不错,为O(logn),但是最坏情况会退化为O(n)。在二叉查找树的基础上进行优化,我们可以使用平衡查找树。平衡查找树中的2-3查找树,这种数据结构在插入之后能够进行自平衡操作,从而保证了树的高度在一定的范围内进而能够保证最坏情况下的时间复杂度。但是2-3查找树实现起来比较困难,红黑树是2-3树的一种简单高效的实现,他巧妙地使用颜色标记来替代2-3树中比较难处理的3-node节点问题。红黑树是一种比较高效的平衡查找树,应用非常广泛,很多编程语言的内部实现都或多或少的采用了红黑树。 除此之外,2-3查找树的另一个扩展——B/B+平衡树,在文件系统和数据库系统中有着广泛的应用。
分块查找
算法简介
要求是顺序表,分块查找又称索引顺序查找,它是顺序查找的一种改进方法。
算法思想
**将n个数据元素”按块有序”划分为m块(m ≤ n)。
** **每一块中的结点不必有序,但块与块之间必须”按块有序”;
** **即第1块中任一元素的关键字都必须小于第2块中任一元素的关键字;
** 而第2块中任一元素又都必须小于第3块中的任一元素,……
**
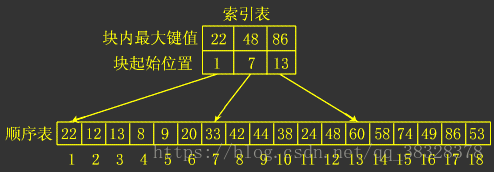
**
算法流程
1、先选取各块中的最大关键字构成一个索引表; 2、查找分两个部分:先对索引表进行二分查找或顺序查找,以确定待查记录在哪一块中; 3、在已确定的块中用顺序法进行查找。
复杂度分析
时间复杂度:O(log(m)+N/m)
哈希查找
算法简介
哈希表就是一种以键-值(key-indexed) 存储数据的结构,只要输入待查找的值即key,即可查找到其对应的值。
算法思想
哈希的思路很简单,如果所有的键都是整数,那么就可以使用一个简单的无序数组来实现:将键作为索引,值即为其对应的值,这样就可以快速访问任意键的值。这是对于简单的键的情况,我们将其扩展到可以处理更加复杂的类型的键。
算法流程
1)用给定的哈希函数构造哈希表; 2)根据选择的冲突处理方法解决地址冲突; 常见的解决冲突的方法:拉链法和线性探测法。 3)在哈希表的基础上执行哈希查找。
复杂度分析
单纯论查找复杂度:对于无冲突的Hash表而言,查找复杂度为O(1)(注意,在查找之前我们需要构建相应的Hash表)。
算法实现
# 忽略了对数据类型,元素溢出等问题的判断。
class HashTable:
def __init__(self, size):
self.elem = [None for i in range(size)] # 使用list数据结构作为哈希表元素保存方法
self.count = size # 最大表长
def hash(self, key):
return key % self.count # 散列函数采用除留余数法
def insert_hash(self, key):
"""插入关键字到哈希表内"""
address = self.hash(key) # 求散列地址
while self.elem[address]: # 当前位置已经有数据了,发生冲突。
address = (address+1) % self.count # 线性探测下一地址是否可用
self.elem[address] = key # 没有冲突则直接保存。
def search_hash(self, key):
"""查找关键字,返回布尔值"""
star = address = self.hash(key)
while self.elem[address] != key:
address = (address + 1) % self.count
if not self.elem[address] or address == star: # 说明没找到或者循环到了开始的位置
return False
return True
if __name__ == '__main__':
list_a = [12, 67, 56, 16, 25, 37, 22, 29, 15, 47, 48, 34]
hash_table = HashTable(12)
for i in list_a:
hash_table.insert_hash(i)
for i in hash_table.elem:
if i:
print((i, hash_table.elem.index(i)), end=" ")
print("\n")
print(hash_table.search_hash(15))
print(hash_table.search_hash(33))python 统计字符串里各个字符出现的次数
from collections import Counter
def austin_test():
c = Counter()
for i in 'programming':
c[i] = c[i] + 1
print c
if __name__ == '__main__':
austin_test()输出结果为:
Counter({'g': 2, 'm': 2, 'r': 2, 'a': 1, 'i': 1, 'o': 1, 'n': 1, 'p': 1})链表
合并两个有序链表(Python)
class Solution:
def mergeTwoLists(self, l1, l2):
# 处理特殊情况
if not l1:
return l2
if not l2:
return l1
pre_head = ListNode(0) # 定义一个临时结点,用于挂载结果
cur = pre_head # 定义当前结点
while l1 and l2: # 如果两个链表当前位置均不为空
if l1.val > l2.val: # 判断两个结点的大小
cur.next = l2 # 将数值较小的结点挂载当前结点后面
l2 = l2.next # 数值较小的结点后移
else:
cur.next = l1
l1 = l1.next
cur = cur.next # 后移当前结点
if l1:
cur.next = l1 # 把链表剩下的部分挂在当前结点
if l2:
cur.next = l2
return pre_head.next # 返回融合后的链表合并两个有序数组
# 合并两个排序数组,生成一个新的数组
def merge(list1, list2):
res = []
i, j = 0, 0
while i < len(list1) and j < len(list2):#都有元素时做比较
if list1[i] <= list2[j]:
res.append(list1[i])
i += 1
else:
res.append(list2[j])
j += 1
# 两个数组长度不一致的时候
res += list1[i:]
res += list2[j:]
return res
# 合并两个排序数组,将nums2的元素插入到nums1中,使得nums1成为一个有序数组
# 先合并到nums1中,再合并
def merge2(nums1, nums2):
nums1 += nums2
nums1.sort()
return nums1
if __name__ == "__main__":
a = [1, 2, 3, 5, 8]
b = [4, 5, 6]
print (merge(a, b))
print (merge2(a, b))
Python反转列表
a=[1,2,3,4,5,6,7,8,9]
b=list(reversed(a))#reversed()函数返回的是一个迭代器,而不是一个List,需要再使用List函数转换一下
c=sorted(a,cmp=None, key=None, reverse=True)#其中reverse=True是按降序排列,reverse=False是按照升序排列
d=a[::-1]#其中[::-1]代表从后向前取值,每次步进值为1Python字符串拼接
请实现有序单项链表反转
LinkedList ReverseSinglyLinkedList(LinkedList list)
{
LinkedList newList; //新链表的头结点
LNode *tmp; //指向list的第一个结点,也就是要摘除的结点
//
//参数为空或者内存分配失败则返回NULL
//
if (list == NULL || (newList = (LinkedList)malloc(sizeof(LNode))) == NULL)
{
return NULL;
}
//
//初始化newList
//
newList->data = list->data;
newList->next = NULL;
//
//依次将list的第一个结点放到newList的第一个结点位置
//
while (list->next != NULL)
{
tmp = newList->next; //保存newList中的后续结点
newList->next = list->next; //将list的第一个结点放到newList中
list->next = list->next->next; //从list中摘除这个结点
newList->next->next = tmp; //恢复newList中后续结点的指针
}
//
//原头结点应该释放掉,并返回新头结点的指针
//
free(list);
return newList;
}判断一个字符串是不是回文
# 方法一、递归切片法
def is_palindrom(s):
"""判断回文数,递归法"""
if len(s) < 2:
return True
if s[0] == s[-1]:
return is_palindrom(s[1:-1])
else:
return False
name1 = 'ABBA'
name2 = '1234'
print(is_palindrom(name1))
print(is_palindrom(name2))
# 方法二、按照字面上的理解,将首尾依次对比:
s = input('请输入一个字符串:')
if not s:
print('请不要输入空字符串!')
s = input('请重新输入一个字符串:')
a = len(s)
i = 0
count = 1
while i <= (a/2):
if s[i] == s[a-i-1]:
count = 1
i += 1
else:
count = 0
break
if count == 1:
print('您所输入的字符串是回文')
else:
print('您所输入的字符串不是回文')
# 法三、采用reversed()函数方法
s = input('请输入一个字符串:')
if not s:
print('请不要输入空字符串!')
s = input('请重新输入一个字符串:')
a = reversed(list(s))
if list(a) == list(s):
print('您所输入的字符串是回文')
else:
print('您所输入的字符串不是回文')请代码实现字符串拼接函数charstrconcat(charpCh1,char*pCh2)
char* strconcat(char * pCh1, char * pCh2)
{
char *result = (char *) malloc(strlen(apCh1) + strlen(pCh2) + 1); //局部变量,用malloc申请内存
if (result == NULL) exit (1);
char *tempc = result; //把首地址存下来
while (*pCh1 != '\0') {
*result++ = *pCh1++;
}
while ((*result++ = *pCh2++) != '\0') {
;
}
//注意,此时指针c已经指向拼接之后的字符串的结尾'\0' !
return tempc;//返回值是局部malloc申请的指针变量,需在函数调用结束后free之
}请设计strconcat的测试用例
二叉树
二叉树遍历
遍历,就是按一定的规则和顺序走遍二叉树的所有结点,使每一个结点都被访问一次,而且只被访问一次。 分为递归算法、非递归算法 递归算法又分为:先序遍历、中序遍历、后序遍历
//输出
void Visit(BiTree T){
if(T->data != '#'){
printf("%c ",T->data);
}
}
//先序遍历
void PreOrder(BiTree T){
if(T != NULL){
//访问根节点
Visit(T);
//访问左子结点
PreOrder(T->lchild);
//访问右子结点
PreOrder(T->rchild);
}
}
//中序遍历
void InOrder(BiTree T){
if(T != NULL){
//访问左子结点
InOrder(T->lchild);
//访问根节点
Visit(T);
//访问右子结点
InOrder(T->rchild);
}
}
//后序遍历
void PostOrder(BiTree T){
if(T != NULL){
//访问左子结点
PostOrder(T->lchild);
//访问右子结点
PostOrder(T->rchild);
//访问根节点
Visit(T);
}
}判断IP合法性(三种方法)
正则表达式判定法
最简单的实现方法是构造一个正则表达式。判断用户的输入与正则表达式是否匹配。若匹配则是正确的IP地址,否则不是正确的IP地址。
\d表示0~9的任何一个数字
{2}表示正好出现两次
[0-4]表示0~4的任何一个数字
| 的意思是或者
1\d{2}的意思就是100~199之间的任意一个数字
2[0-4]\d的意思是200~249之间的任意一个数字
25[0-5]的意思是250~255之间的任意一个数字
[1-9]\d的意思是10~99之间的任意一个数字
[1-9])的意思是1~9之间的任意一个数字
.的意思是.点要转义(特殊字符类似,@都要加\转义)
import re
def check_ip(ipAddr):
compile_ip=re.compile('^(1\d{2}|2[0-4]\d|25[0-5]|[1-9]\d|[1-9])\.(1\d{2}|2[0-4]\d|25[0-5]|[1-9]\d|\d)\.(1\d{2}|2[0-4]\d|25[0-5]|[1-9]\d|\d)\.(1\d{2}|2[0-4]\d|25[0-5]|[1-9]\d|\d)$')
if compile_ip.match(ipAddr):
return True
else:
return False字符串拆解法
把ip地址当作字符串,以.为分隔符分割,进行判断
#!/usr/bin/python
import os,sys
def check_ip(ipAddr):
import sys
addr=ipAddr.strip().split('.') #切割IP地址为一个列表
#print addr
if len(addr) != 4: #切割后列表必须有4个参数
print "check ip address failed!"
sys.exit()
for i in range(4):
try:
addr[i]=int(addr[i]) #每个参数必须为数字,否则校验失败
except:
print "check ip address failed!"
sys.exit()
if addr[i]<=255 and addr[i]>=0: #每个参数值必须在0-255之间
pass
else:
print "check ip address failed!"
sys.exit()
i+=1
else:
print "check ip address success!"
if len(sys.argv)!=2: #传参加本身长度必须为2
print "Example: %s 10.0.0.1 "%sys.argv[0]
sys.exit()
else:
check_ip(sys.argv[1]) #满足条件调用校验IP函数引入IPy类库
IPy库是一个处理IP比较强大的第三方库。涉及到计算大量的IP地址,包括网段、网络掩码、广播地址、子网数、IP类型等别担心,Ipy模块拯救你。Ipy模块可以很好的辅助我们高效的完成IP的规划工作。 IPy库的安装方法请根据自己的操作系统自行查找,有很多详细例子。
import IPy
def is_ip(address):
try:
IPy.IP(address)
return True
except Exception as e:
return False给定一个String类型对象,如何判断其是一个IPV4的字符串
IPV4地址由4个组数字组成,每组数字之间以.分隔,每组数字的取值范围是0-255。
IPV4必须满足以下四条规则:
1、任何一个1位或2位数字,即0-99; 2、任何一个以1开头的3位数字,即100-199; 3、任何一个以2开头、第2位数字是0-4之间的3位数字,即200-249; 4、任何一个以25开头,第3位数字在0-5之间的3位数字,即250-255。
这样把规则全部罗列出来之后,构造一个正则表达式的思路就清晰了。
首先满足第一条规则的正则是:\d{1,2} 首先满足第二条规则的正则是:1\d{2} 首先满足第三条规则的正则是:2[0-4]\d 首先满足第四条规则的正则是:25[0-5]
把它们组合起来,就得到一个匹配0-255数字的正则表达式了:
(\d{1,2})|(1\d{2})|(2[0-4]\d)|( 25[0-5])
IPV4由四组这样的数字组成,中间由.隔开,或者说由三组数字和字符.和一组数字组成,所以匹配IPV4的正则表达式如下:
(((\d{1,2})|(1\d{2})|(2[0-4]\d)|(25[0-5])).){3}((\d{1,2})|(1\d{2})|(2[0-4]\d)|(25[0-5]))
public static void matchAndPrint(String regex, String sourceText){
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(sourceText);
while(matcher.find()){
System.out.println(matcher.group());
}
}
public static void main(String[] args) {
String regex = "^(((\\d{1,2})|(1\\d{2})|(2[0-4]\\d)|(25[0-5]))\\.){3}((\\d{1,2})|(1\\d{2})|(2[0-4]\\d)|(25[0-5]))$";
matchAndPrint(regex, "23.135.2.255");
matchAndPrint(regex, "255.255.0.256");
matchAndPrint(regex, "0.0.0.0");
}比较两个版本号的大小
比较两个版本号ver1和ver2的大小
1、首先将两个版本号处理成纯数字的版本号,如5.2.1.3.20
2、将版本号按“.”切割为列表,从索引0开始依次比较列表的大小
3、对比两个列表的len,len较短的作为循环次数,防止列表索引越界
4、如果循环结束后仍没有对比出结果,则对比列表len,len值大的为高版本
def compared_version(ver1, ver2):
"""
传入不带英文的版本号,特殊情况:"10.12.2.6.5">"10.12.2.6"
:param ver1: 版本号1
:param ver2: 版本号2
:return: ver1< = >ver2返回-1/0/1
"""
list1 = str(ver1).split(".")
list2 = str(ver2).split(".")
print(list1)
print(list2)
# 循环次数为短的列表的len
for i in range(len(list1)) if len(list1) < len(list2) else range(len(list2)):
if int(list1[i]) == int(list2[i]):
pass
elif int(list1[i]) < int(list2[i]):
return -1
else:
return 1
# 循环结束,哪个列表长哪个版本号高
if len(list1) == len(list2):
return 0
elif len(list1) < len(list2):
return -1
else:
return 1
result = compared_version("10.12.2.6.5", "10.12.2.6")
print(result)括弧匹配问题
#-*- coding: utf-8 -*-
BRANKETS = {'}':'{',']':'[',')':'('}
BRANKETS_LEFT, BRANKETS_RIGHT = BRANKETS.values(), BRANKETS.keys()
def bracket_check(string):
"""括号匹配检测函数"""
stack = []
for char in string:
# 如果是左括号
if char in BRANKETS_LEFT:
# 入栈
stack.append(char)
# 右括号
elif char in BRANKETS_RIGHT:
# stack不为空,并且括号匹配成功
if stack and stack[-1] == BRANKETS[char]:
# 出栈
stack.pop()
# 匹配成功
else:
return False
return not stack
def main():
print(bracket_check('{brace*&^[square(round)]end}'))
print(bracket_check('{brace*&^[square(round])end}'))
if __name__ == '__main__':
main()测开常考代码题目
测试开发岗面试时对代码能力要求不太高,刷熟剑指offer就可以大胆地去面试啦~
下面是我总结的百度美团京东等大厂常见的代码题
1.将一个只含有-1和1的乱序数组变成-1全在1前面的数组 2.合并区间 3.最小覆盖子串 4.最长不含重复字符的字符串 5.翻转单词顺序 6.判断回文串 7.两数之和 8.最长回文子串 9.和为K的子数组 10.合并两个有序数组 11.合并两个有序链表 12.判断链表有环、环的位置、环的长度 13.翻转链表 14.奇偶链表 15.合并n个有序链表 16.去除驼峰字符串 17.统计一个数字在排序数组中的出现次数 18.输入YYYY-MM-DAY 判断是当年的第多少天 19.括号匹配 20.判断是否为合法字符 21,冒泡排序 归并排序 快速排序 22.最长连续数列 23.给出数组的所有子集 24.两个栈实现一个队列 25.寻找数组中前三大的值 26.两个排序数组找到相同元素